サンプリング Data sampling
ランダムサンプリング
国立国語研究所では従来ランダムサンプリングによる語彙調査を実施してきました。特定の母集団(例えば199X年に出版された○○新聞)を対象として、そこから無作為に単語を抽出する方法です。ランダムサンプリングは、母集団の持つ特徴を正確に推定するための統計学的手法が確立されている点で、非常にすぐれたサンプリング方法だといえます。
KOTONOHAの現代書き言葉均衡コーパスにおいても、基本的にはランダムサンプリングによってデータを集めます(実際には、現代日本語をできるだけ幅広く観察するために、ランダムではないサンプリングも併用します)。以下ではまず出版データを母集団としたランダムサンプリングの方法について説明します。
母集団の捉え方
ランダムサンプリングを実施するためには前もって母集団を決めなければなりません。そのためにまず書き言葉とは何かを決めることにします。書き言葉には様々なものがありますが、ここでは活字になって刊行されたものを対象として考えることにします。具体的には書籍、新聞、雑誌などであり、これらは不特定多数の読者を想定して書かれているという意味で、ある程度公的な書き言葉だと考えられます。
反対に日記や手紙の類は母集団から除外します。これらの日本語に価値がないわけではありませんが、日記や手紙などの私的な書き言葉はその全体量を知ることができませんので、母集団に含めることが不適切と考えられるのです。
新聞や雑誌の範囲をどのように設定するかも問題になります。新聞ならば、全国紙だけか、地方紙も含めるのか、スポーツ紙、業界紙はどうするか、といった問題です。このような問題には正解があるわけではありません。コーパスの利用目的をよく考えながら母集団の範囲を決定していくことにします。
サンプリングのための層別
次に母集団に含まれる各メディア(書籍、新聞、雑誌など)をさらに下位区分します。例えば書籍の場合、図書館で利用されている日本十進分類法(NDC)を利用して本の内容による層別が可能です。
例えば2001~2005年に出版された書籍の推定総文字数と日本十進分類法(NDC)の関係は以下の表のようになります。この表に従うと「総記」には書籍データ全体の3.37%を、また「文学」には19.25%をそれぞれ割り当てることになります。このような層別によってサンプルの偶然の偏りを避けることができますし、母集団に対する推定の精度も若干向上します。
層別のためのデータは各種の出版年鑑や書籍情報のデータベースから入手することができます。
| NDC | 総文字数 | 構成比 |
|---|---|---|
| 0. 総記 | 1,636,414,548 | 3.37% |
| 1. 哲学 | 2,597,610,813 | 5.35% |
| 2. 歴史 | 4,301,204,340 | 8.86% |
| 3. 社会科学 | 12,408,321,943 | 25.56% |
| 4. 自然科学 | 5,069,594,034 | 10.44% |
| 5. 技術工学 | 4,615,929,967 | 9.51% |
| 6. 産業 | 2,196,387,437 | 4.53% |
| 7. 芸術 | 3,258,432,447 | 6.71% |
| 8. 言語 | 888,800,128 | 1.83% |
| 9. 文学 | 9,341,275,486 | 19.25% |
| n. 記録なし | 2,225,954,208 | 4.59% |
| 合 計 | 48,539,925,351 | 100.0% |
サンプルの選択
具体的に個々のサンプルをどのように選ぶかを説明します。まず本の1ページをランダムに選択します。例えば、下の左側の図が選ばれたページとします。

次にそのページ全体を上の右側の図のように区切り、100個の交点のなかから一つをランダムに選びます(図中の赤い矢印参照)、そして、その交点にもっとも近い文字から数えて、定められた長さの文字列(1000字)を「固定長サンプル」として採用します。その際、広告、図表、写真、挿絵などはサンプルの対象外とします。
雑誌や新聞からサンプルを採る方法も基本的には同じです。しかし雑誌や新聞は、活字の組み方が書籍よりも複雑なので、文字を数えるのが書籍よりも大変です。
サンプルの長さ(固定長サンプルと可変長サンプル)
「汎用コーパスの設計上の問題点」でも触れたように、利用目的によってサンプルの長さが違ってきます。現代日本語書き言葉均衡コーパスでは、汎用性を高めるために、比較的短い長さの一定分量のサンプルと文脈を考慮した長めのサンプルとの2種類のサンプルを設計しました。前者を固定長サンプル、後者を可変長サンプルと呼びます。出版サブコーパス、図書館サブコーパスからは、これら2種類のサンプルを同時に取得します。
固定長サンプル
ランダムに選んだ文字を基準として、1000文字を抽出するサンプルです。この1000文字は、句読点や符号は含まず数えます。サンプルの先頭や末尾は文の途中になりますが、検索の際に文脈がきちんと表示されるように、入力は文単位で行います。また、数える対象にはしない句読点や符号もそのまま入力します。抽出比が正確であることから語彙調査、文字調査などの統計的分析に向いています。
可変長サンプル
ランダムに選んだ点を基準として、ある章や節など文章構成上のまとまりを一つのサンプルとします。章や節の長さは一定ではありませんから、短いサンプルも長いサンプルも存在します。ただし、あまりに長大になると偏りが生じますので、最大でも1万字という制限を設けています。談話研究や文章構造の分析に向いています。
いろいろな母集団
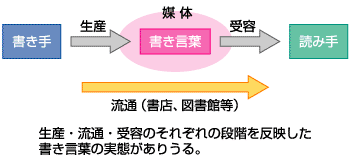
上で母集団として採用したのは、書き言葉がどれだけ出版されたか(生産実態)に関する統計でしたが、これが唯一可能な母集団ではありません。例えば書き言葉がどれだけ受容されたかに基づく母集団を考えることができます。世の中には出版はされたものの、ほとんど読まれないで終わる本もありますから、受容ないし需要に基づく母集団を考えることには積極的な意味があります。しかし活字の受容に関する統計は簡単には入手できませんから、このような母集団を実際に利用することは困難です。
生成と受容の中間に流通という段階を想定することもできます。書店に並んでいる本や図書館に収蔵されている本は流通段階にあると考えられます。書店に並んでいる本のデータは入手できませんが、図書館のデータは入手できますので、これを母集団とみなすことができます。
東京都立中央図書館の御厚意により、東京都内の52自治体の図書館が収蔵する図書のデータを入手できました。全体で1563万冊の書籍が収蔵されていますが、そこには大量の重複があります。重複を除いて異なり冊数を計算すると約114万冊です。これらの本は何らかの形で実際に需要が存在した本とみなすことができます。もちろん多くの図書館に共通して収蔵されている本を選べば、それだけ需要の高かった本を選ぶことになります。
どの程度の共通度がよいかは目的によりますが、ここでは、出版目録に基づく母集団と分量を合わせるため、13館以上で共通して収蔵している書籍を母集団としました。
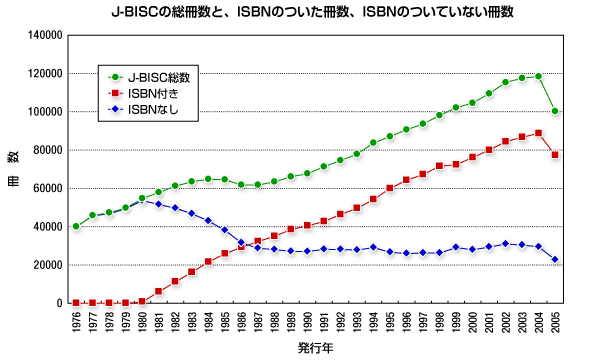
図書館の収蔵書籍からのサンプリングは、ISBN(国際標準図書番号)という書籍に付けられたIDをもとに行います。ただし、我が国でISBNの付与が始まったのは1981年で、その普及には少し時間がかかりました。
上の図は、国立国会図書館の蔵書目録であるJ-BISCにおけるISBNが付された書籍と付けられていない書籍の数を経年的に調べたものです。ISBNが付けられていない書籍の減少が止まるのが1987年ごろです。それ以降はほぼ一定の割合でISBNのない書籍が存在しますが、これは主に官公庁資料などと思われます。そこで、ISBNの付与がほぼ安定したと思われる1986年を母集団の開始時期としました。実際、1986年には大手出版社ではISBNの付与はほぼ完了しています。