【重要】
現在、国立国語研究所では『現代日本語書き言葉均衡コーパス』(BCCWJ)の拡張として、『現代日本語書き言葉均衡コーパス 第2部』(BCCWJ2)を構築しています。
これに伴い、これまで『現代日本語書き言葉均衡コーパス』(BCCWJ)として公開してきたコーパスの名称を『現代日本語書き言葉均衡コーパス 第1部』(BCCWJ1)に変更します。
このページでは『現代日本語書き言葉均衡コーパス 第1部』(BCCWJ1)について掲載しています。『現代日本語書き言葉均衡コーパス 第2部』(BCCWJ2)は対象外です。
設計の基本方針 Basic design policy
均衡コーパスの必要性
2000年代冒頭の時点で考えると、日本語コーパスの最大の問題点は、日本語の全体をバランスよく反映したコーパスがないことでした。
例えば、新聞社の中には過去の記事を全文データベースとして有償で公開しているところがあり、その総量は数億語にのぼります。しかし、新聞記事だけでは、たとえ対象を書き言葉だけに限るとしても、日本語の全体像を把握することはできません。雑誌記事の日本語は新聞記事とはどこかで明らかに異なっていますし、文学作品の日本語については言うまでもありません。小説などの文学作品については「青空文庫」関係者の努力によって、数多くの作品が万人に利用可能な形で公開されています。しかし、これらはいずれも著作権が消滅した作品ですから、少なくとも50年以上昔の日本語です。
以上をまとめると、日本語学における従来のコーパス言語学的な分析には以下のような問題点がありました。
- 新聞CD-ROMや電子化された文学作品など手近な資料の分析に偏りがちであること
- その資料が日本語のどの部分を代表していて、どの部分を代表していないかが明確でないこと
- 従って、資料から得た情報にどれくらい妥当性があるか、どれくらい普遍性があるかが不明であること
- 資料が公開されていないため、第三者による検証ないし再現ができないこと
均衡コーパス設計の基本方針
このような問題を解決するために以下の方針に沿ったコーパスを設計しました。
- 日本語の実態のできるだけ正確な縮図となるコーパス、いわゆる均衡コーパス(balanced corpus)を目指します。そのために統計的母集団からのランダムサンプリングを実施します。
- 現代日本語の縮図というからには、母集団が狭すぎてはなりません。国立国語研究所が従来実施してきた語彙調査では、新聞、雑誌、中学・高校教科書などをそれぞれ別個に扱ってきましたが、今後は、それらの全体に一般書籍をくわえ、さらにインターネット上の文書なども加えて、現代日本語の書き言葉全体をひとつの母集団とみなす観点が必要です。
- せっかくコーパスを構築しても、それを公開できなければ意味がありません。著作権処理を実施して、公開可能なコーパスとします。
- 国立国語研究所がこれまでに公開したコーパスともできるだけ互換性を保持することが望まれます。そこで、先に公開した『日本語話し言葉コーパス』の解析単位との互換性を図ります。
汎用コーパス設計上の問題点
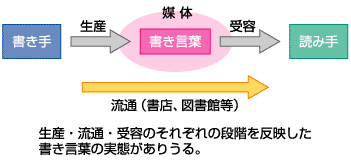
コーパスに汎用性を持たせようとすると、幾つか問題が生じます
コーパスの利用目的によってサンプリングの仕様も異なってきます。従来の国立国語研究所の語彙調査のように、語彙の多様性を追求するためには、数十字程度の小さなサンプルを大量に抽出するのが好適ですが、談話分析や意味分析に使うためには、文脈の理解が大切であり、数千字規模の大きなサンプルが望まれます。
そもそも現代日本語の「実態」とは何かという点も問題になりえます。下の図のように書き言葉の「生産」「流通」「受容」の各過程に注目することがありえるからです。これらはいずれも書き言葉の実態を捉える上で積極的な意味を持つ過程です。
これらのうち、「生産」と「流通」はサンプルを抽出する際に利用する既存のデータがありますが、「受容」の過程は、既存の適切なデータがなく、新たに大規模なアンケートを実施するなど大きな労力を必要とするため、今回の設計には「受容」の過程を反映するデータはありません。
現代日本語書き言葉均衡コーパスの構成
上記の問題を多少なりとも解決するために、性質の異なる 3 つのサブコーパスを構築しました。出版(生産実態)サブコーパス、図書館(流通実態)サブコーパス、特定目的サブコーパスです。出版サブコーパスは生産実態を、図書館サブコーパスは流通実態をそれぞれ反映するものです。特定目的サブコーパスは、ウェブのテキストなど、 上記 2 つのサブコーパスでは集められないテキストを中心に、個別の研究目的に沿うデータを集めたものです。
なお、上に述べたように、テキストの取得に大きな手間が掛かるため、受容の実態を反映するサブコーパスは作成しませんでした。以下、それぞれのサブコーパスについて解説します。

3種類のサブコーパス
出版(生産実態)サブコーパス
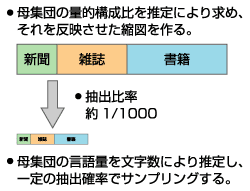
上図の左上、緑色の部分が出版(生産実態)サブコーパスです。出版目録から得た情報に基づき母集団を設定し、そこからランダムに選ばれたサンプルを収録しています。書き言葉の生産の側面を把握するためのサブコーパスです。
- サブコーパスの規模は約3500万語。
- 書籍、雑誌、新聞を収録対象とする。
- 個々のサンプルの長さは、固定長(1000字)及び可変長(1万字を上限とする 章や節のまとまり)の2種類。
- 収録する資料の刊行年代は、2001~2005年。
サンプリングに関しては、一定期間(例えば1年)に生産された総文字数を推定し、そこから一定の抽出比でサンプルをランダム抽出する。文字数の推定のためには、新聞ならば任意の1週間分の紙面に現れる文字を実際に数え、そこから1年分の文字数を推定する。書籍の場合は、国立国会図書館の蔵書目録などをもとに書籍の総ページ数を数え、1ページあたりに含まれる平均文字数から総文字数を推定する。推定の際は版型の違いや日本十進分類の違いを考慮する。
図書館(流通実態)サブコーパス
上図の右上、紫色の部分が図書館(流通実態)サブコーパスです。単に出版されただけでなく、ある程度広い範囲に流通したことが確認されているテキストを対象とします。実際には、東京都下の公共図書館の協力を得て、その収蔵図書を母集団とみなし、そこからランダムに選ばれたサンプルを収録します。書き言葉の「流通」実態を把握するためのサブコーパスです。
- サブコーパスの規模は約3000万語。
- 書籍を収録対象とする。
- 個々のサンプルの長さは、固定長(1000字)及び可変長(1万字を上限とする章や節のまとまり)の2種類。
- 収録する資料の刊行年代は、1986~2005年。
図書館サブコーパスにおける母集団は、出版サブコーパスにおける書籍の母集団と量を合わせる。これにより、ほぼ同じ抽出比でサンプルを獲得することができる。出版サブコーパスにおける書籍の母集団は文字数にして485.4億字と推定される。これにもっとも近いのが、東京都下の13自治体以上の図書館で共通に収蔵されている書籍の文字数(478.8億字)である。
特定目的サブコーパス
上図の下側、灰色の部分が非母集団(特定目的)サブコーパスです。ここには、日本語にとって重要でありながら上記2つのサブコーパスには含まれにくいデータや、差し迫った言語問題の解決に向けて国立国語研究所をはじめとする関係機関が利用するためのデータを収録します。
- サブコーパスの規模は約3500万語。
- 書籍、広報紙、Web上の書き言葉などを対象とする。
- 個々のサンプルの長さは、可変長(1万字を上限とする章や節のまとまり)。
一部の資料は、固定長(1000字)及び可変長(1万字を上限とする章や節のまとまり)。 - 収録する資料の刊行年代は様々。最長1976~2005年。
- ランダムサンプリングによらずサンプルを取得するものがある。
具体的には以下のようなデータを格納します。ベストセラー、白書、検定教科書、広報紙、Web掲示板(Yahoo!知恵袋)、ブログ(Yahoo!ブログ)、韻文、法律、国会会議録
著作権処理と個人情報の保護
『現代日本語書き言葉均衡コーパス』は、原文の表現のままを収録するのが原則ですが、例外として個人情報保護法に抵触する情報があればテキストの該当部分を伏せ字としています。場合によってはサンプル全体を除外することも行っています。
個人情報保護法には抵触しなくても、著作権者からの希望があれば、情報の一部を伏せ字とします。例えば新聞社からの要請で、新聞記事中の「~容疑者」「~被害者」等の実名部分を伏せ字にしています。