まとめて検索『KOTONOHA』
- まとめて検索『KOTONOHA』とは?
- 『KOTONOHA』マニュアル
まとめて検索『KOTONOHA』とは?
「まとめて検索『KOTONOHA』」は、『中納言』のコーパス選択画面の上部にあり、複数のコーパスを同時に検索し、その集計結果をグラフ化 して視覚的に観察できるサービスです。『中納言』の利用登録をすれば使うことができます。

国立国語研究所がこれまで提供してきた従来のコーパス検索システム『中納 言』は、現代日本語書き言葉均衡コーパス(BCCWJ)や日本語話し言葉コーパス(CSJ)といったコーパスをそれ ぞれ"個別"の画面で検索し、結果を閲覧するサービスでした(個別検索)。これに対してKOTONOHAは、「まとめ て検索」の名前の通り、中納言の中のコーパスを1度にまとめて検索し、その集計結果をユーザに表示します。 これを専門的な用語で「包括的検索」「串刺し検索」「横断検索」と言ったりします。こうした検索を実現する ためには、それぞれのコーパスが何かしら統一された枠組みの中で構築されている必要がありますが、国立国語 研究所には電子化辞書『UniDic』という、単語 (短単位)を斉一に認定し、管理していく枠組みがあ ります。中納言の中のコーパスはいずれもUniDicの中の単語として斉一に切り出され、UniDicの形態論情報が付 与されています。そのため我々は特に不自由を感じることなく、それぞれのコーパスをまたいで単語を検索し、 調べたい単語について各コーパスでの出現状況を俯瞰的に観察できます。そのためのツールが、KOTONOHAです。
使用例1: 任意の単語について、書き言葉と話し言葉での使用を比較できます。
「けれど」という表現は書き言葉よりも、話し言葉でよく使われていることがわかります。
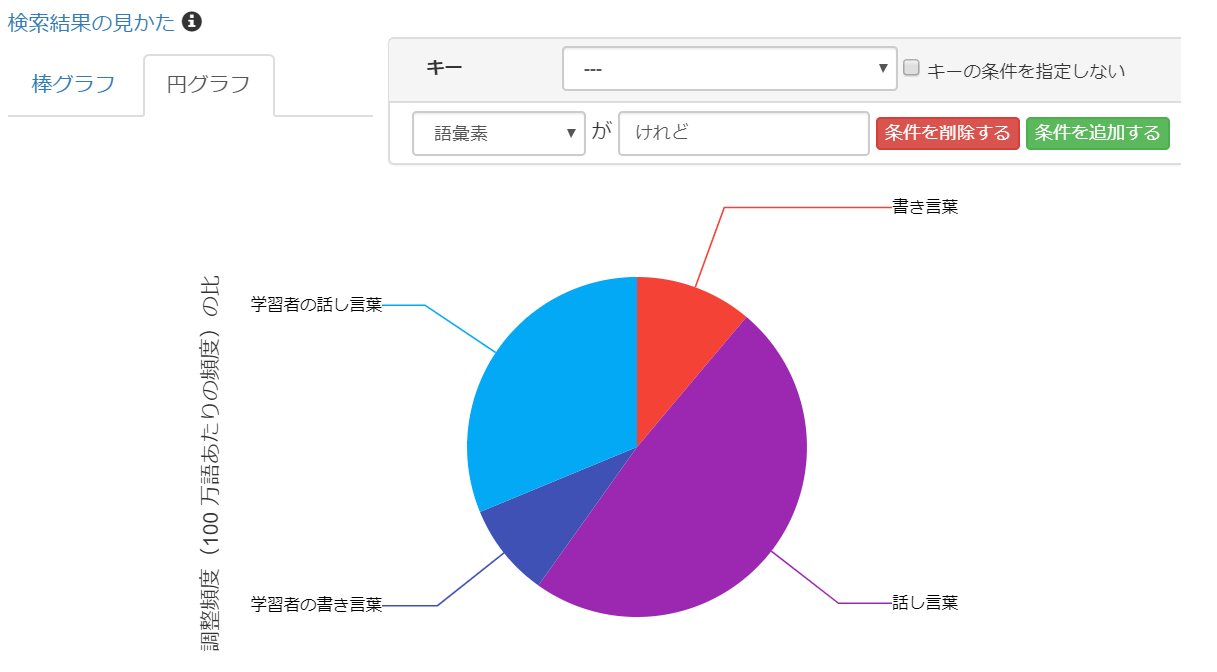
クリックすると拡大します
使用例2: 任意の単語について、時代ごとの使用の変化を観察できます。
「恋しい」という表現の使用が現代に向かうにつれ、減少傾向にあることがわかります。
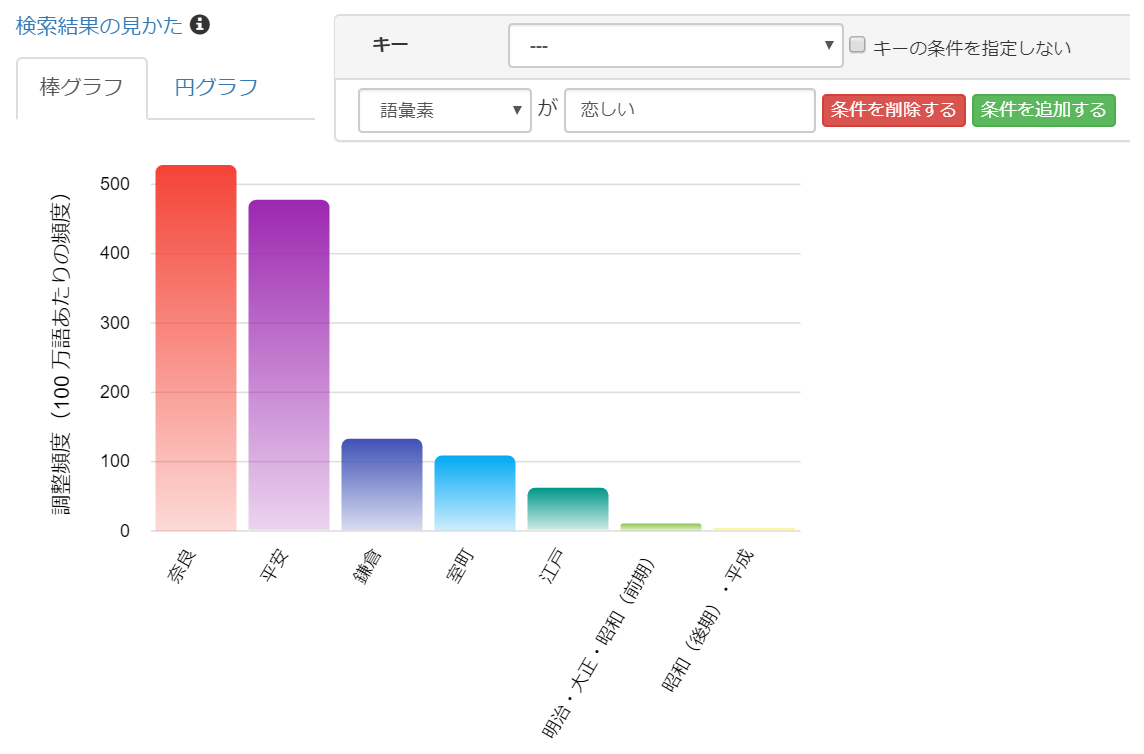
クリックすると拡大します
利用における注意点
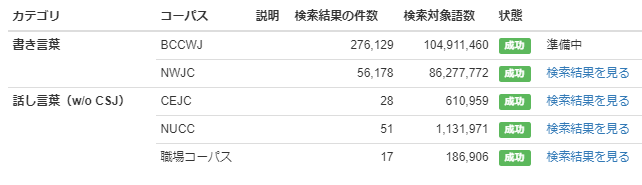
KOTONOHAはバックグラウンドで中納言検索系を使っている都合、コーパスのまとめて検索を完全な形で利用するには、 中納言上で各コーパスの利用申請・利用許諾を得た上で、下図のように中納言内のコーパスすべてを検索できる状態にしておかないといけません。
中納言で利用可能なコーパスがすべてではない場合(下図のようにすべてにチェックがついていない場合は)、利用可能なコーパスの検索結果のみ表示されます。また、検索対象内のカテゴリ (例:検索対象「話し言葉・書き言葉」の「話し言葉」)に属するコーパスすべてが利用可能な場合に限り、カテゴリ内の調整頻度が表示されます。
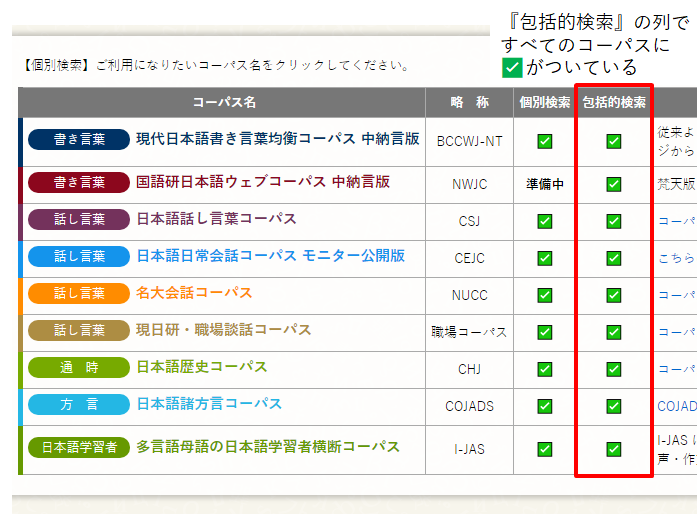
『KOTONOHA』マニュアル
ページTop検索条件の指定
KOTONOHAの検索方法は、基本的にBCCWJ中納言版の検索フォームで検索と同じで、 検索したい単語(キー)の条件を指定して、「検索する」ボタンを押すだけです。 ただし、BCCWJ中納言版と異なり、短単位検索しかサポートしていません。 これは中納言内のコーパス検索で統一的に実装されているのが短単位検索のみだからです。
| キーの種類 | 指定方法 |
|---|---|
| 書字形出現形 | 文字列を入力 |
| 語彙素 | 文字列を入力 |
| 語彙素読み | 文字列を入力(全角カタカナのみ) |
| 語形(基本形) | 文字列を入力(全角カタカナのみ) |
| 品詞 | 大分類/中分類/小分類による選択式 |
| 活用型 | 大分類/中分類/小分類による選択式 |
| 活用形 | 大分類/小分類による選択式 |
| 書字形(基本形) | 文字列を入力 |
| 発音形出現形 | 文字列を入力(全角カタカナのみ) |
| 語種 | 選択式 |
条件は複数指定可能で、「条件を追加する」ボタンで条件入力ボックスを追加できます。
また指定の条件を削除したい場合は、「条件を削除する」ボタンでボックスごと消すことができます。
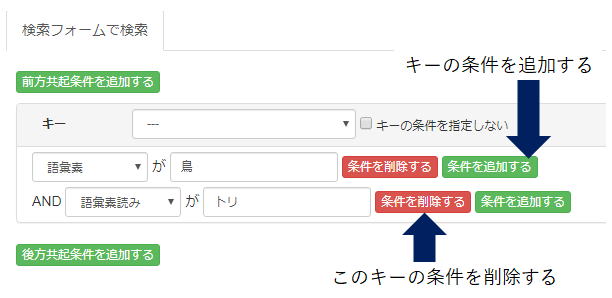
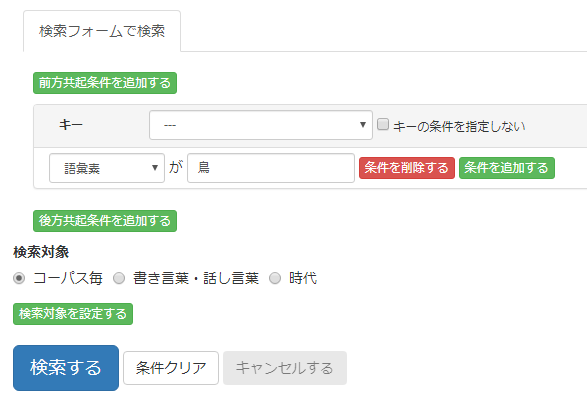
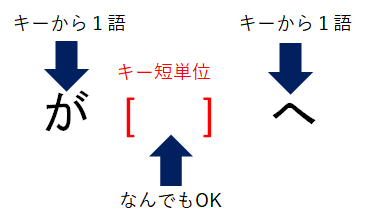
条件はキー(短単位)だけでなく、その前後の短単位についても指定が可能です。
「前方共起条件を追加する」ボタンで、キーより先の位置で出現する短単位の条件、
「後方共起条件を追加する」ボタンで、キーより後の位置で出現する短単位の条件がそれぞれ指定可能です。
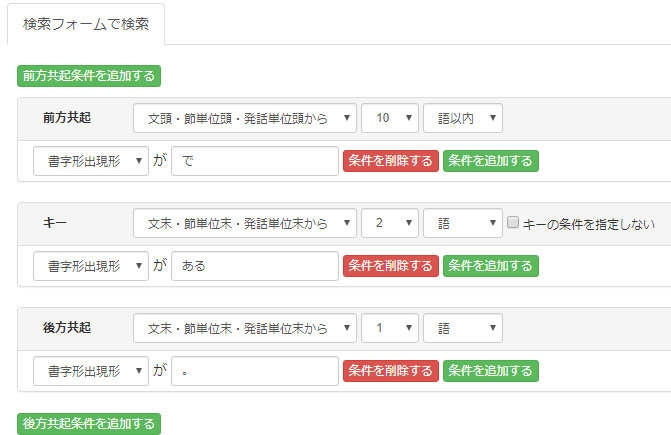
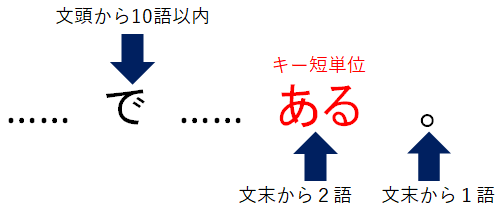
「前方」「後方」いずれも直前直後の1短単位のみでなく、キーから10短単位以内の、範囲もしくは相対位置で指定できます。
またキーからでなく、前方共起条件ならば「文頭・節単位頭・発話単位頭から」、後方共起条件ならば「文頭・節単位頭・発話単位頭から」を指定することも可能で、
キー自体もこれら2つの出現位置指定が可能となっています。
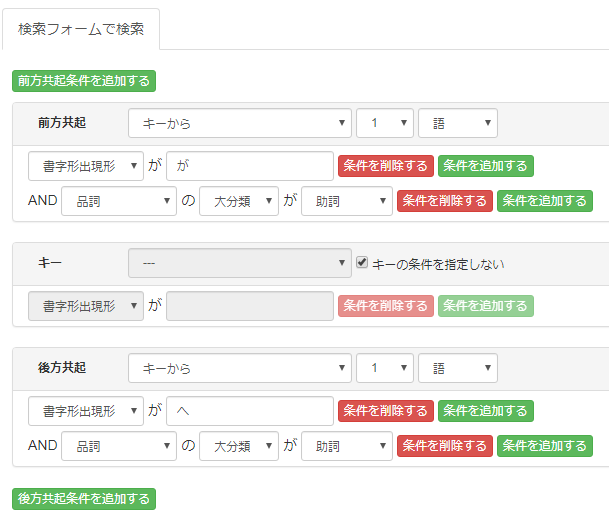
前方共起条件もしくは後方共起条件(あるいはその両方)を使うと、キーの条件を指定しない(ブランクにする)ことも可能です。
指定した条件は「検索する」ボタン右の「条件クリア」で初期状態へ、リセット可能です。
検索対象の選択
KOTONOHAでは、ラジオボタン「検索対象」から、以下の3種類の検索を行うことができます。
- コーパス毎:各コーパス毎の集計結果を表示
- 書き言葉・話し言葉:コーパスを「書き言葉」「話し言葉」のカテゴリに分け、それぞれで集計した結果を表示
- 時代:時代別に集計した結果を表示
検索対象は上記1~3以外に、「検索対象を設定する」ボタンからユーザが自由に設定することもできます。 詳しくは[応用編] 検索対象のカスタマイズを参照してください。
ページTop検索結果の見かた
KOTONOHAの大きな特徴は、指定した検索条件の検索結果(条件に一致した件数)を、グラフを使い視覚的に表示できる点にあります。 例えば、次のような検索条件を指定します。検索対象は「コーパス毎」です。
検索結果は以下のように表示されます。
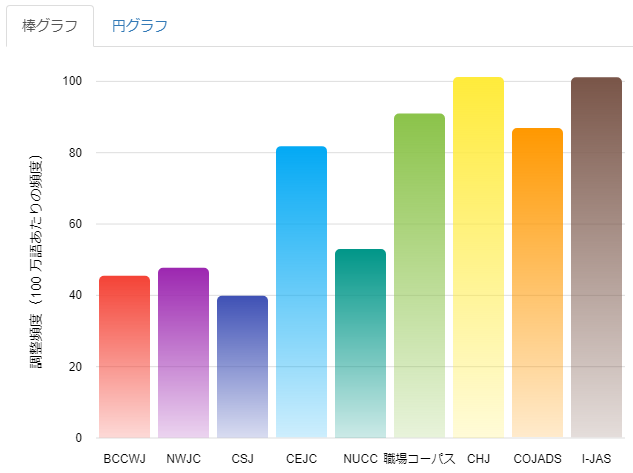
検索対象を「コーパス毎」に指定しているため、
横軸は各コーパス名、縦軸は調整頻度です。
これを見ると、「トリ-鳥」という語彙素が各コーパスにまんべんなく現れていることがわかります。
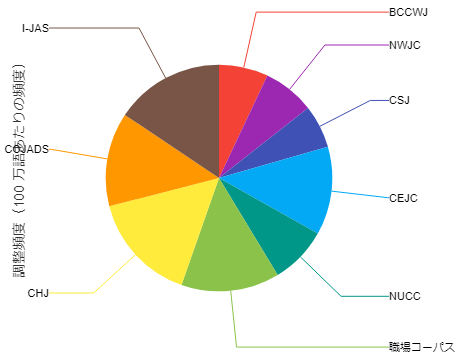
グラフ上部のタブで、棒グラフと円グラフの切り替えが可能になっています。
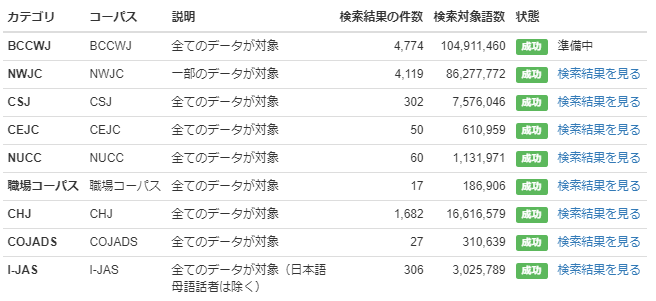
実際の検索結果の件数や、検索したコーパスの規模の統計データもグラフと共に表示されます。 調整頻度のグラフはコーパス全体を俯瞰してみるのには適していますが、実際の頻度 の値を見てみると、コーパスの規模が大きく異なっていることもあるので、グラフはあくまで検索結果を眺める 入り口だと思ってください。
「グラフの画像をダウンロードする」「検索結果の表をダウンロードする」ボタンをクリックすると、結果 をダウンロードすることができます。
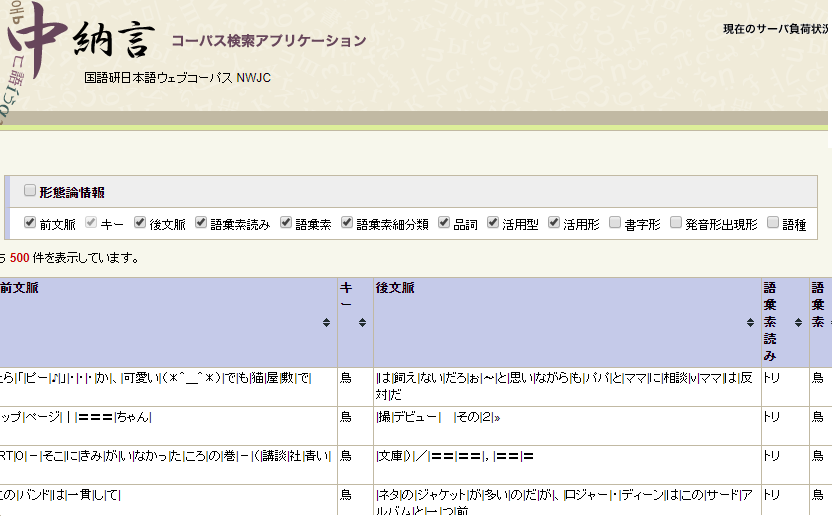
コーパスごとの検索結果の表にある「検索結果を見る」リンクをクリックすると、コーパスごとに前後文脈を含めたキーの詳細な出現を確認できます。
まとめると、KOTONOHAの基本的な使い方は、以下のような流れになります。

ケーススタディ1:書き言葉・話し言葉
具体的な問題について、KOTONOHAを使って調べてみましょう。 例えば、「だ・である調」は、話し言葉よりも書き言葉でよく使われている印象があります。 検索対象を「書き言葉・話し言葉」にして調べてみます。
検索条件は次の通りです。「検索対象」で「書き言葉・話し言葉」を選択します。
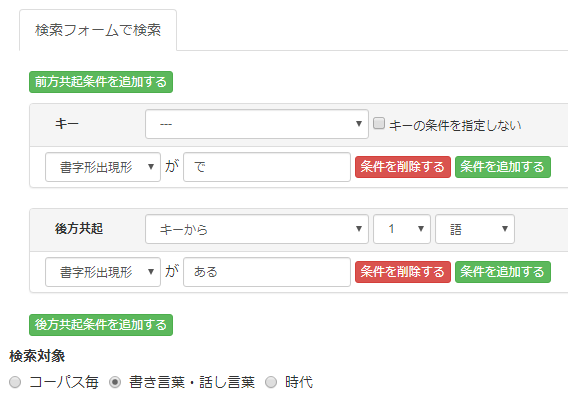
結果は以下のようになりました。
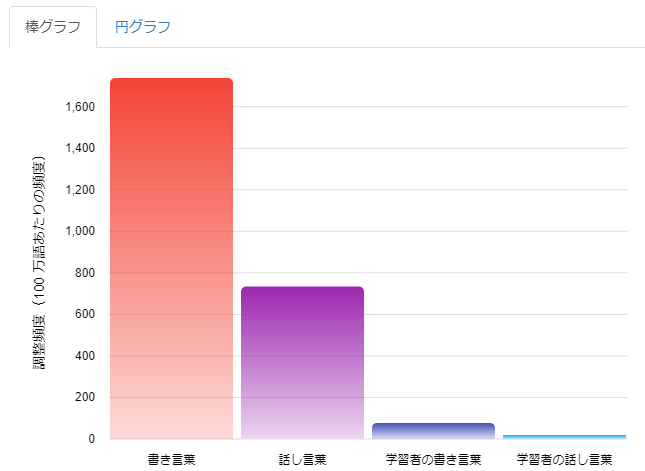
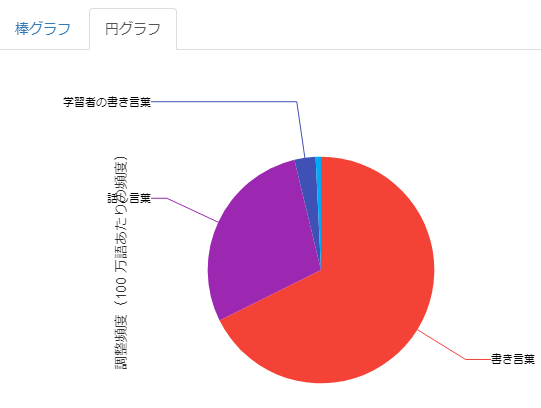
このグラフを見ると「で|ある」は話し言葉よりも書き言葉で多く出現していることが一目でわかります。
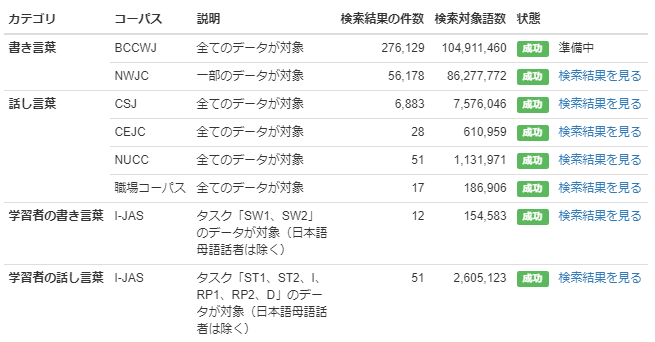
一方、詳細な値を確認すると、話し言葉の中でもCSJに多く「で|ある」が出現していることがわかりました。 実は、CSJには模擬講演や学会講演の独話データが多く含まれていて、 そういった場ではくだけた口調よりも「だ・である調」が使われることが多いのです。 「検索結果を見る」をクリックして、実際の用例を確認してみましょう。
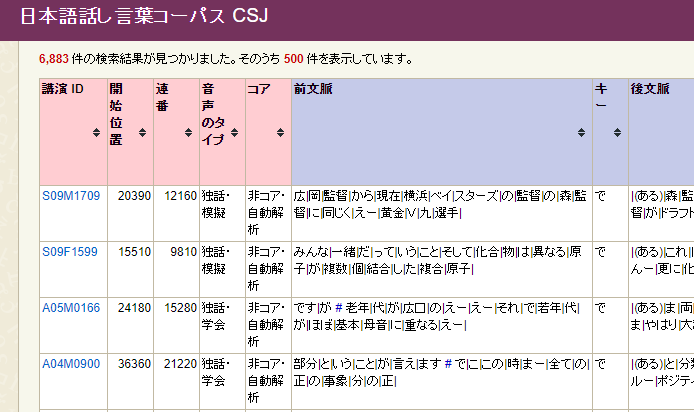
検索対象のカスタマイズ機能「検索対象を設定する」を用いれば、話し言葉カテゴリからCSJのみを取り除いた結果を見ることもできます。
ただし、少し複雑な使い方になるため、詳細は[応用編] 検索対象をカスタマイズするで別途解説します。
ケーススタディ2:歴史
ケーススタディ1で扱った「だ・である調」は、歴史的にみると明治時代の言文一致の中で普及してきました。 そこで、今度は検索対象を「時代」に変えて、「で|ある」を検索してみます。 検索条件はケーススタディ1と同じです。ただし、検索対象を「時代」に変更します。
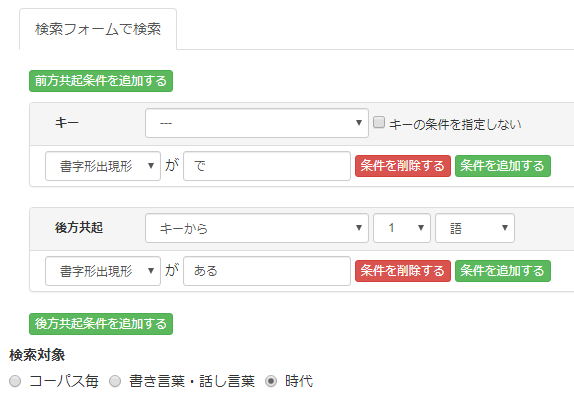
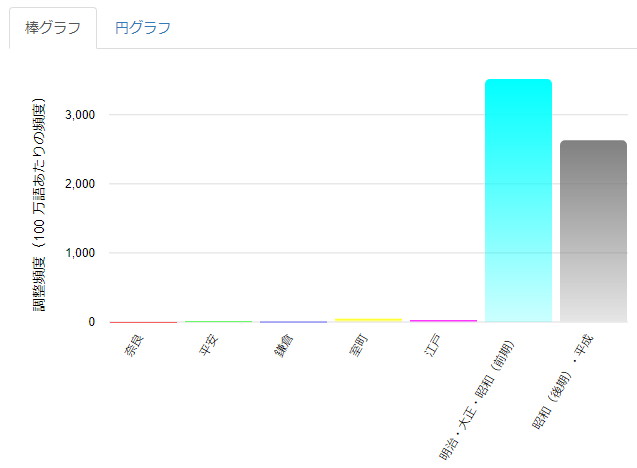
結果は以下のとおりです。明治・大正・昭和(前期)からグラフが一気に伸びあがることが分かります。
[応用編] 検索対象の確認・カスタマイズ
ページTop検索対象の確認
KOTONOHAにデフォルトで実装されている検索対象は、 「コーパス毎」「書き言葉・話し言葉」「時代」の3種類でした。 ここでは、これらの3つの検索対象が、それぞれどのコーパスを検索に使っており、その中でどのようにカテゴリ分けしているのか確認する方法を説明します。
検索対象の下部にある「検索対象を設定する」ボタンを押すと、下のような「検索対象の設定」ポップアップが現れます。
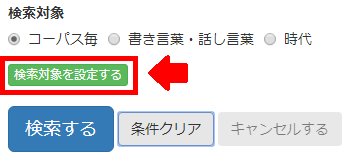
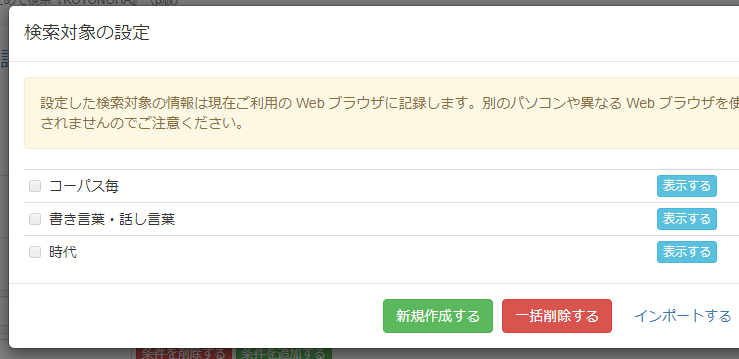
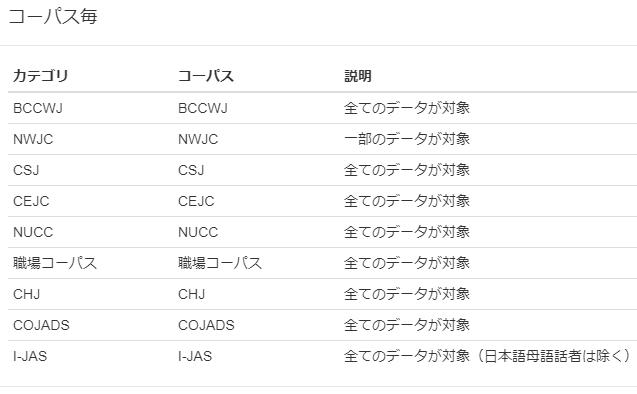
検索対象の右にある「表示する」ボタンを押すと、この検索で使用するコーパスの一覧が表示されます。 例えば、「書き言葉・話し言葉」の右にある「表示する」ボタンをクリックすると下のような表が現れ、 どのコーパスがどのカテゴリに属しているかを確認できます。

ここでは、
カテゴリ:書き言葉
・BCCWJ
・SHC
カテゴリ:話し言葉
・CSJ
・CEJC
・CEJC-Child
・SSC
・NUCC
・CWPC
となっていることがわかります。
学習者の書き言葉・話し言葉はいずれもI-JASを使っていますが、 I-JAS内部の区分でカテゴリ検索に使う個所が指定されており、 その指定方法が「説明」列に記載されています。
検索対象「コーパス毎」では名前の通り、各コーパスがそのままカテゴリとして設定されています。
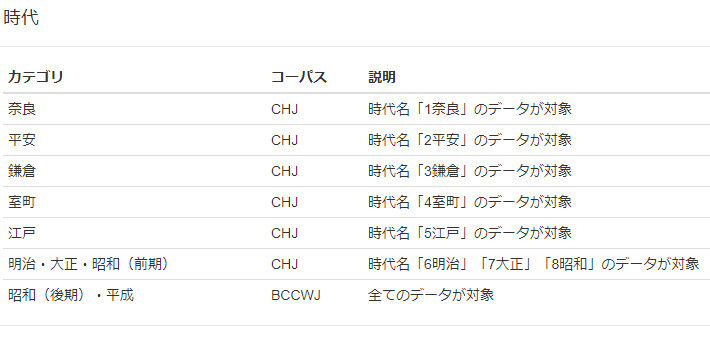
検索対象「時代」を見ると、時代区分とコーパスの対応関係が分かります。
検索対象のカスタマイズ
KOTONOHAにデフォルトで実装されている検索対象は、「コーパス毎」「書き言葉・話し言葉」「時代」の3種 類ですが、ユーザ自身が「まとめて検索」したいコーパスやその下位区分を任意に指定し、その分類を使っ て検索を実行することができます。
注) 新規作成した検索対象は、現在ご利用中のWebブラウザに記憶されます。別のWebブラウザでも同じ検索対象を追加したい場合は、別途新規作成していただくか、右下にある「インポートする」「エクスポートする」メニューを使って検索対象の情報をコピーする必要があります。
ケーススタディ1では、CSJに「で|ある」表現が多く含まれていることが分かりました。 ここではカテゴリ「話し言葉」からCSJを取り除いた「話し言葉(w/o CSJ)」という新しいカテゴリを持った 新しい検索対象「書き言葉・話し言葉(w/o CSJ)」を作成してみます。
検索対象の下部にある「検索対象を設定する」ボタンを押し、表示された「検索対象の設定」ポップアップで「新規作成する」を選びます。
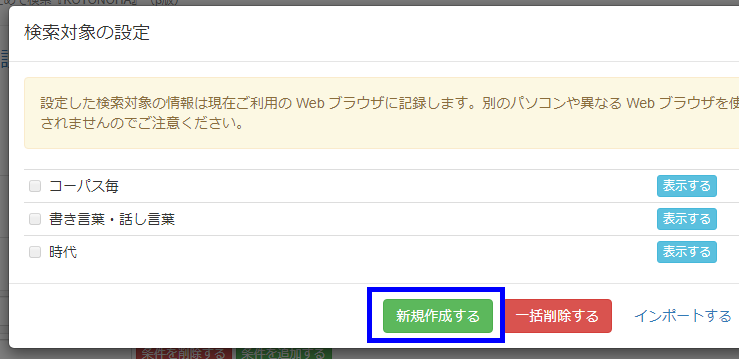
「検索対象の編集」ポップアップが表示されるので、「カテゴリを追加する」を押します。
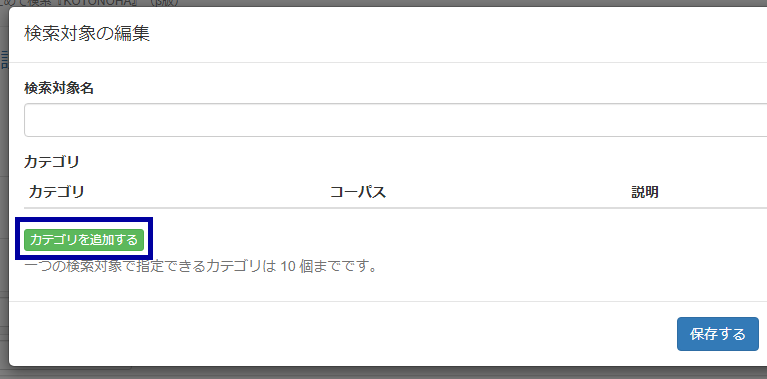
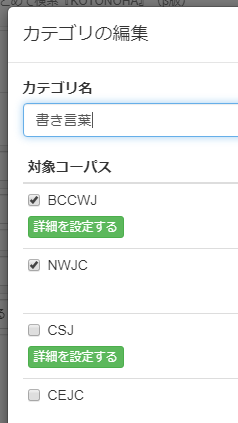
「カテゴリ名」を「書き言葉」とし、BCCWJ(現代日本語書き言葉均衡コーパス)とSHC(昭和・平成書き言葉コーパス)にチェックを入れ(デフォルトの検索対象「書き言葉・話し言葉」と同様のカテゴリ)、最後に右下の「保存する」を押します。
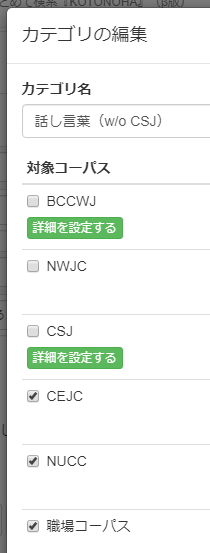
同様に「カテゴリを追加する」で、今度は「カテゴリ名」を「話し言葉(w/o CSJ)」として、CSJ以外の話し言葉コーパスにチェックを入れ、保存します。
コーパスの内部を分けて検索対象を設定する場合は、コーパス名の下にある「詳細を設定する」ボタンをクリックします。
これで「書き言葉」と「話し言葉(w/o CSJ)」の2つのカテゴリが用意できたので、「検索対象名」を「書き言葉・話し言葉(w/o CSJ)」として「保存する」を押します。
あとから各カテゴリの中身を編集したくなった場合は、各カテゴリの一番上の行右側の「編集する」を押せば、「カテゴリの編集」に戻れます。
またその隣の「削除する」で、当該カテゴリを削除します。
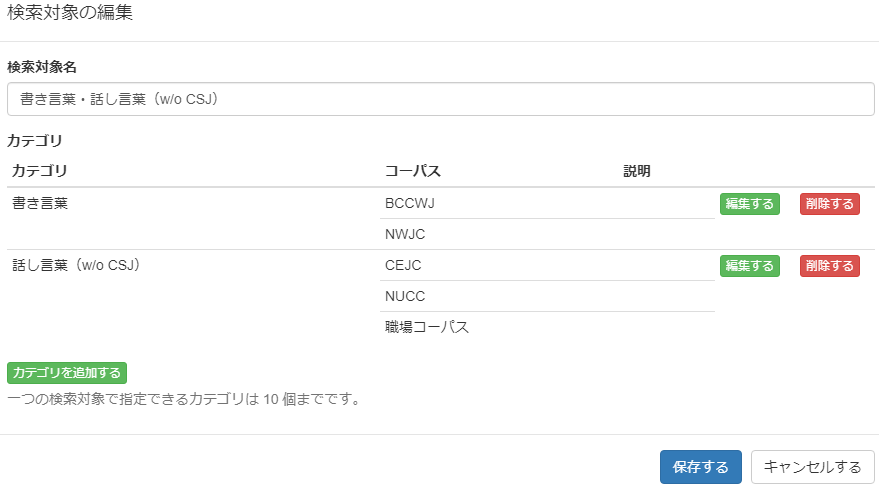
保存した検索対象「書き言葉・話し言葉(w/o CSJ)」が既存の3つの検索対象の 下に新たに追加されました。
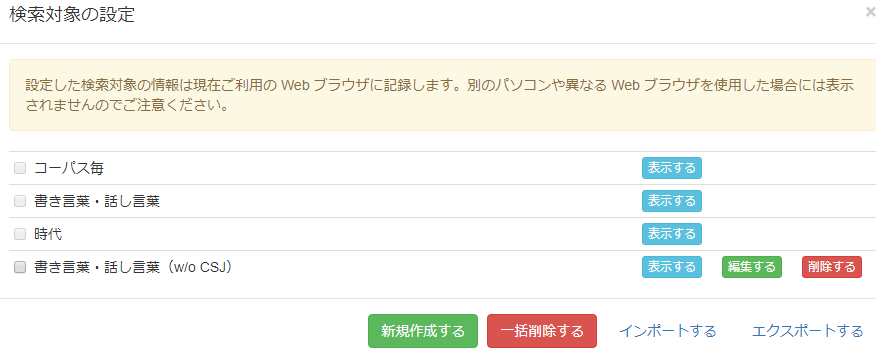
またポップアップ右上「×」でポップアップを閉じると検索対象ラジオボタンにも「書き言葉・話し言葉(w/o CSJ)」が追加されています。
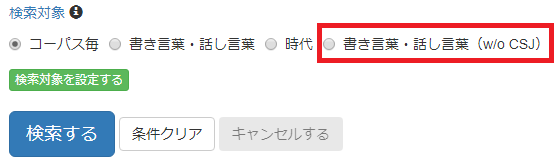
作成した検索対象「書き言葉・話し言葉(w/o CSJ)」を使って、 ケーススタディ1の「で|ある」検索を行なってみます。
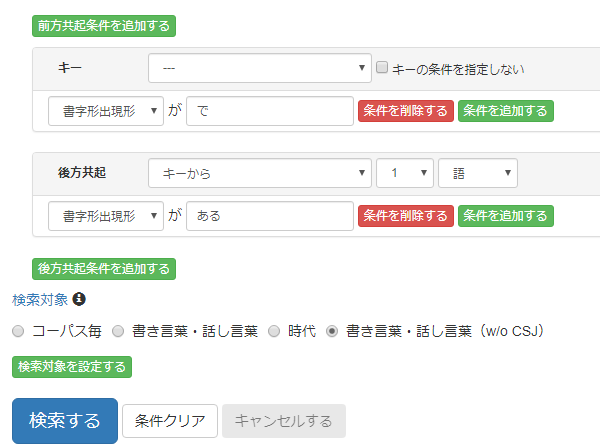
結果は次のようになりました。
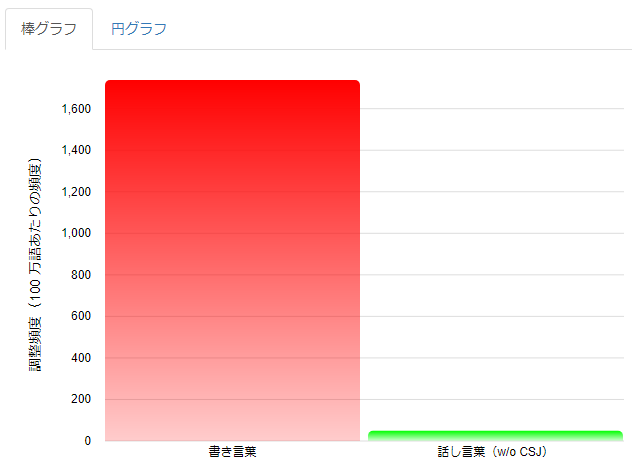
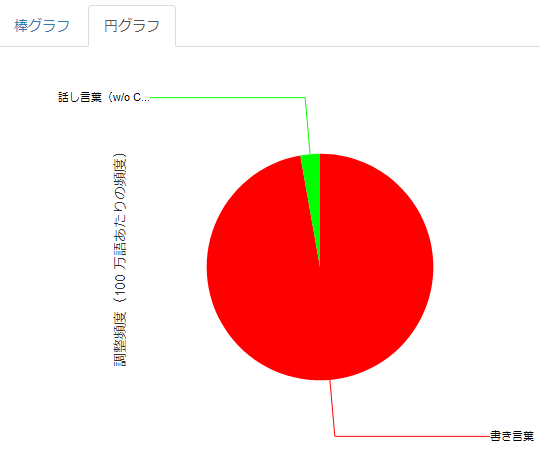
CSJを話し言葉のカテゴリから取り除くと、「で|ある」の書き言葉と話し言葉での使用傾向がより明確になることが確認できました。
コーパスの内部を分けて検索対象を設定する
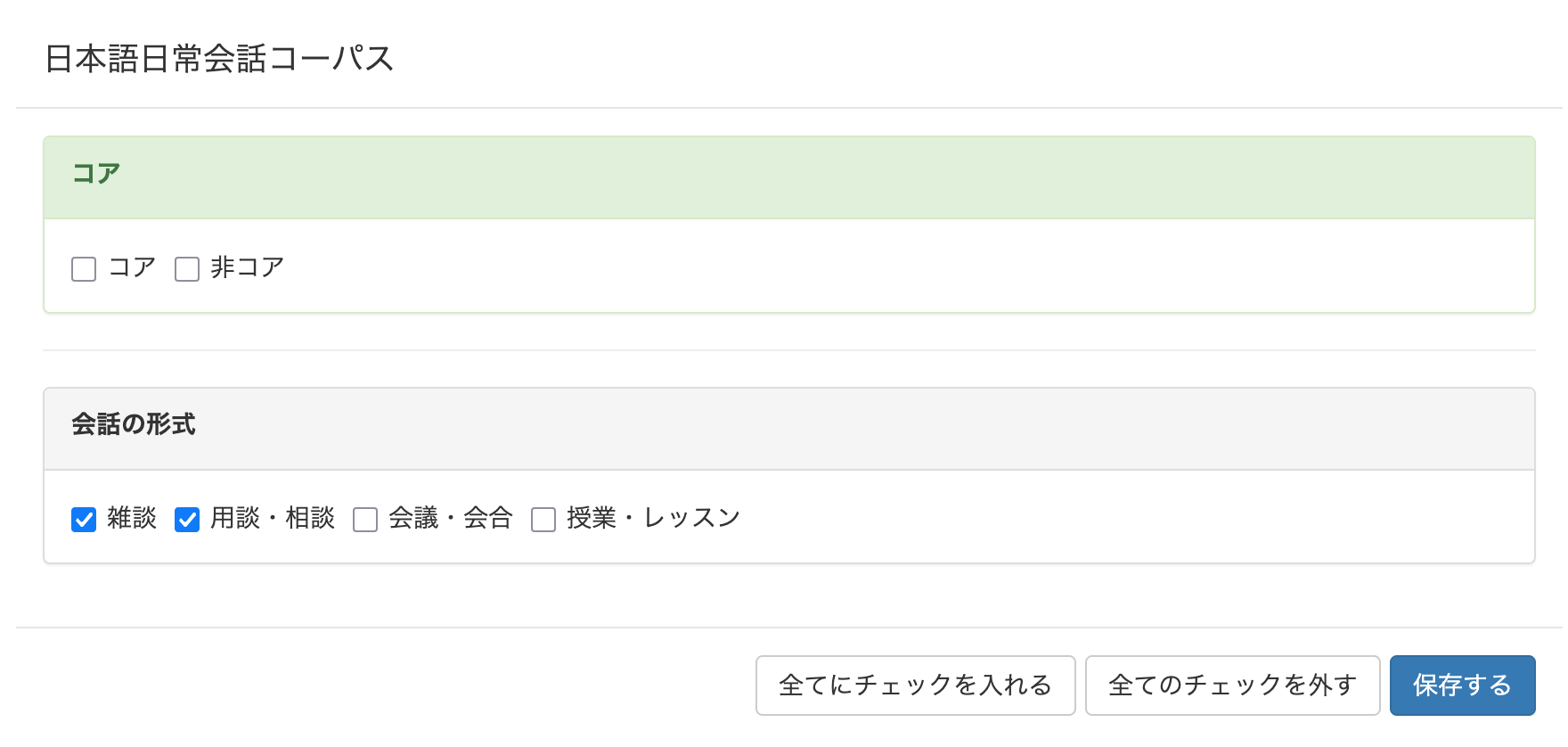
コーパス名の下にある「詳細を設定する」ボタンを押せば、コーパスの内部をさらに細かく分けて設定することもできます。 下の図は、CEJCの「詳細を設定する」ボタンを押したときに表示される画面です。
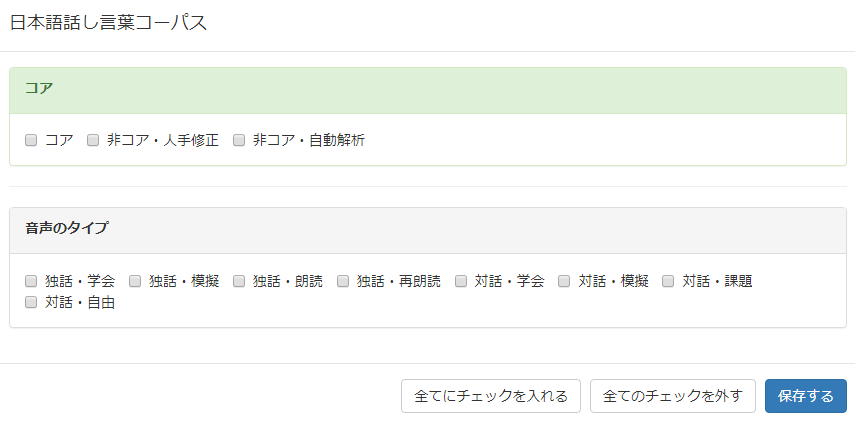
枠で囲まれた中にあるすべての項目にチェックがない場合は、すべての項目が選択されます。枠の中にチェックされている項目が1つでもある場合は、チェックされていない項目が対象から外れます。下の図では、「コア」「非コア」の両方が対象で、会話の形式としては「雑談」「用談・相談」が検索対象になります。
ページTop
調整頻度とは?
グラフ表示に使われている「調整頻度」について解説します。
サイズ(検索対象語数)の大きく異なる2つコーパス間で単語の出現頻度を比較しようとしたとき、 極端な例、もし一方のコーパスのサイズが1万語規模(コーパスS)であったとして、もう片方が100億語の規模(コーパスXL)だとします。 そして、ある単語wのコーパスSでの出現回数が10、コーパスXLでは1万だったとします。 このとき、10と1万という数をそのまま比較しても意味がありません。 単語wの現れたコーパスのサイズ(分母)がまったく違うので、その大きさに合わせた頻度の「調整」が必要になります。 この際、各コーパスサイズに合わせて修正した単語wの頻度が「調整頻度」です。 一番単純な方法は単語wの出現回数を各コーパスの総語数で割って相対頻度に直すことですが、 コーパスの分野でよく用いられるのが、PMW(Per Million Words)です。 KOTONOHAでも調整頻度としてPMWを採用しています。
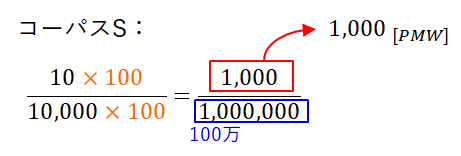
PMWでは、単語wの100万語当たりの出現頻度を計算します。 つまり、分母となるコーパスサイズが100万語となるよう、分子分母の比率を保ったまま相対頻度の分母(コーパスの総語数)を100万語に調整し、 その分子(調整後の単語wの出現回数)だけを取り出します。 コーパスSは1万語規模なので、分母に100をかければ100万語になります。 よって、コーパスSで10回現れた単語wのPMWは1000です。 対して、コーパスXLは100億語規模なので、分母を1万で割れば100万語になります。よって、コーパスXLで1万回現れた単語wのPMWは1です。
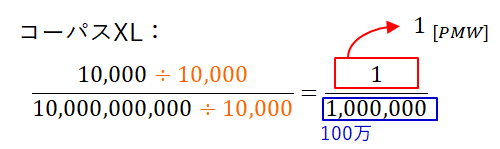
このようにPMWで比較すると、単語wはコーパスSでコーパスXLよりも多く出現していることになります。 ただし、1万語中にたった10回しか現れなかった単語の頻度をそのまま信用していいのでしょうか? 10回という出現回数はあまりに少なく、もしかすると偶然で、コーパスのサンプリング次第では0回であった可能性も捨てきれません。 そのため調整頻度はあくまで目安として、コーパスを分析していく際にはもともとのコーパスサイズや出現頻度、 そしてその出現事例を詳しくみていく必要があるのです。