M-XML(統合形式XMLデータ)詳細 M-XML
M-XML形式のデータはDisc1のM-XMLディレクトリの下に、サブコーパスごとにディレクトリ分けされて格納されている。ディレクトリ内にそれぞれ一つの圧縮ファイルがあり、これを展開することで1ファイルが1サンプルに対応する多数のXMLファイルが展開される。ファイル数の多いLB、PB、OC、OYについては、複数のサブディレクトリに分けてXMLファイルが展開される。
M-XML(統合形式XMLデータ)は、C-XML(文字ベースXML)フォーマットをもとにして、可変長・固定長サンプルを統合し、言語構造を一定程度反映させたXMLフォーマットである。短単位・長単位の形態論情報を、階層構造を維持したまま埋め込み、言語構造に関わる情報を扱いやすくしている。XMLファイルの符号化形式はUTF-8(BOMなし)である。
可変長と固定長の統合
C-XMLでは、可変長サンプルと固定長サンプルが別のXML文書として構造化されている。しかし、二種類のサンプルは同一の文書から採集されているため、多くの部分が重複している。こうしたデータに形態論情報を付与し整備する場合には、同一内容のテキストを二回処理する必要がないように、統合して扱うことができた方が望ましい。しかし、タグが交叉することになるため、別の構造を持つ二つのXMLを単純に統合することはできない。そこで、統合形式では次のような方法で可変長と固定長を統合することとした。
そもそも、文書構造を意識して採集された可変長サンプルとは違い、均一な長さのサンプルを取得する目的で作られた固定長サンプルでは、文書構造を示すブロック要素タグは大きな意味を持たない。そこで、M-XMLでは、可変長サンプルの文書構造だけを保持し、固定長の範囲は形態素(長単位)に付与する属性で示すこととした。可変長部分から固定長部分がはみ出している場合には、はみ出した部分を単純なコンテナ(<div type="fiexdLength">)で囲み、インライン要素だけを保持した。
M-XMLは次のような属性を持つmergedSample要素をルートとして上記の要素をまとめ上げている。
<mergedSample sampleID="サンプルID" type="BCCWJ-MorphXML" version="1.0">
異なる文書定義の統合
C-XMLは、サブコーパスによっては異なる文書定義(DTD)が用いられている。知恵袋(OC)、ブログ(OY)、教科書(OT)、韻文(OV)は、おおよそ共通の構造を持ちながらも、一般の可変長サンプルとは異なるそれぞれ独自の文書定義によっている。そのため、すべてのデータを統一的に処理しようとするとき問題となる場合がある。
そこで、M-XMLでは、タグセットを一部変更して、すべてのサブコーパスについて共通の文書定義で処理できるようにしている。C-XMLに比較してやや緩い制約での検証になるが、すべてのXMLファイルは単一のXMLスキーマで検証済みである。この統合に際してサブコーパス独自のタグを次のように一部変更している。
OC : <OCQuestion> → <article articleID="サンプルID-Question">
<OCAnswer> → <article articleID="サンプルID-Answer">
OC, OY: <br type='physicalLine_original /> → <webBr/>
OT : <root> → <squareRoot>
形態論情報の階層構造
BCCWJにおける短単位・長単位・文節は、その定義から入れ子構造をなす。文節はこれが連なって文を構成するし、短単位は文字から構成されるから、BCCWJの形態論情報は、結局次のような言語単位の階層構造の中に位置づけられることになる。
文章/文/文節/長単位/短単位/文字
文書構造タグや階層化された形態論情報を活用するためには、この階層構造・包含関係がそのままXMLフォーマットに反映されることが望ましい。この考え方に従い、M-XMLでは、次のような構造で形態論情報を付与した。
以下はそのサンプルとして一つの文(sentence要素)を抜き出したものである(見やすさのため一部の属性を省略している)。
<LUW B="B" SL="v" l_lemma="公共工事請け負い金額" l_lForm="コウキョウコウジウケオイキンガク" l_wType="混" l_pos="名詞-普通名詞-一般" >
<SUW lemma="公共" lForm="コウキョウ" wType="漢" pos="名詞-普通名詞-一般" pron="コーキョー">
公共
</SUW>
<SUW lemma="工事" lForm="コウジ" wType="漢" pos="名詞-普通名詞-サ変可能" pron="コージ">
工事
</SUW>
<SUW lemma="請け負い" lForm="ウケオイ" wType="和" pos="名詞-普通名詞-一般" pron="ウケオイ">
請負
</SUW>
<SUW lemma="金額" lForm="キンガク" wType="漢" pos="名詞-普通名詞-一般" pron="キンガク">
金額
</SUW>
</LUW>
<LUW SL="v" l_lemma="の" l_lForm="ノ" l_wType="和" l_pos="助詞-格助詞" >
<SUW lemma="の" lForm="ノ" wType="和" pos="助詞-格助詞" pron="ノ">の</SUW>
</LUW>
<LUW B="B" SL="v" l_lemma="動き" l_lForm="ウゴキ" l_wType="和" l_pos="名詞-普通名詞-一般" >
<SUW lemma="動き" lForm="ウゴキ" wType="和" pos="名詞-普通名詞-一般" pron="ウゴキ">
動き
</SUW>
</LUW>
(略)
</sentence>
短単位タグ(SUW)の属性
埋め込まれた短単位タグ(SUW)には以下の属性が付与されている。※印の属性は、出力する必要がない場合には、値だけでなく属性自体の出力を行っていない。
| 属性名 | 備考 |
|---|---|
| start | 原文文字列のサンプル頭からのオフセット値(10きざみ) |
| end | |
| orderID | 連番(TSVの連番と互換) |
| lemma | 語彙素 |
| lForm | 語彙素読み |
| subLemma | 語彙素細分類 ※区別がある場合のみ出力 |
| wType | 語種 |
| pos | 品詞 |
| cType | 活用型 ※活用語のみ出力 |
| cForm | 活用形 ※活用語のみ出力 |
| formBase | 語形 |
| usage | 用法 ※区別がある場合のみ出力 |
| orthBase | 書字形 ※活用語のみ出力 |
| originalText | 原文文字列 ※要素となるテキスト(=書字形出現形)と異なる場合のみ出力 |
| kanaToken | 仮名形出現形 ※語形と異なる場合のみ出力 |
| pronToken | 出現発音形 |
なお、TSVにおける書字形出現形は、SUWタグが囲んでいるテキストに相当する。
仮名形出現形は、テキストに対する読みがな(あるいはIMEで入力する場合のカナ文字列)に相当するものである。
※参照:TSVデータ詳細
長単位タグ(LUW)の属性
埋め込まれた長単位タグ(LUW)には次の属性が付与されている。※印の属性は、出力する必要がない場合には、値だけでなく属性自体の出力を行っていない。
| 属性名 | 備考 |
|---|---|
| B | 文・文節境界 文節境界=B,文境界=S |
| SL | サンプル長 固定長=f,可変長=v | l_lemma | 語彙素 |
| l_lForm | 語彙素読み |
| l_wType | 語種 |
| l_pos | 品詞 |
| l_cType | 活用型 ※活用語のみ出力 |
| l_cForm | 活用形 ※活用語のみ出力 |
| l_formBase | 語形 |
| l_orthBase | 書字形 ※活用語のみ出力 |
TSVにおける「長短一致」など、XMLの構造や、子要素となる短単位のタグから容易に取得可能な情報は属性としては付与していない。
文字ベースのXML(C-XML)から変更したタグ
上で示した形態論情報の階層にC-XMLの諸要素を当てはめるならば、以下の図「形態論情報付きXMLフォーマットの階層構造」のような階層構造が考えられる(色網掛けはすべてのテキストに必須の要素)。しかし、このときC-XMLにおける諸要素がこの階層と齟齬を来すことが問題となる。M-XMLでは、以下のようにC-XMLのタグを修正することで対処している。
形態論情報付きXMLフォーマットの階層構造
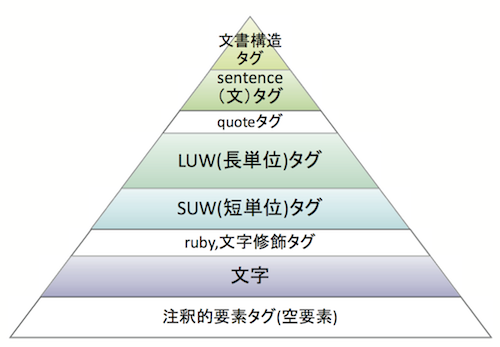
A. 文(sentence)タグ
C-XMLでは、文を示すsentenceタグに入れ子を許しており、大きな文の中に複数の文が何重にも含み込まれることがある。たとえば、次のように文中に引用がある場合には、全体をsentenceで囲みつつ、引用部分もsentenceでマークアップされている。
「<sentence>落ちた、落ちたって言わないでよ。</sentence>
<sentence type="quasi">結構辛がってるんだから</sentence>」</quote>
言って夕美子は目を伏せ、(中略)うつむいている。</sentence>
入れ子になった複雑な文であることを示すこのマークアップには積極的な意味があるが、(1) 上位のsentenceがきわめて長くなる場合がある (2) 形態素解析などの入力となる「文」を定めがたい (3) データを文番号で管理できない、などの問題がある。
そこでM-XMLでは、文タグの階層を整備するために、sentenceの入れ子を認めることをやめ、上位の文はsuperSentenceとして文書構造タグの一種とした。下位のsentenceはそのまま残し、superSentenceの直下に当たる部分を新たにsentence で囲みtype= " fragment "とした。
<sentence type="fragment">驚きながらそう誤魔化した構治の言葉に、</sentence>
<quote><sentence>「落ちた、落ちたって言わないでよ。</sentence>
<sentence type="quasi">結構辛がってるんだから」</sentence></quote>
<sentence type="fragment">言って夕美子は目を伏せ、(中略)うつむいている。</sentence>
</superSentence>
B. インライン要素
センテンスの内側に入る要素でもタグが形態論情報と齟齬を来す場合があるため、次のように対処した。
-
ルビ(ruby)
BCCWJでは、ふりがなは原則として一文字ごとに付与しているが、熟字訓や臨時的な読みでは複数文字をrubyタグで囲んでいる。たとえば次のような例がある。
1) 語彙(い) (短単位よりも短いルビ)
2) 時雨(しぐれ) (短単位と一致するルビ)
3) 喜(ケー)望(プタ)峰(ウン) (短単位よりも長いルビ)
4) 新しい(アール・)芸術(ヌーヴォー) (長単位よりも長いルビ)
これらはC-XMLでは次のようにタグ付けされている。
1a) <SUW>語<ruby rubyText="い">彙</ruby></SUW>
2a) <SUW><ruby rubyText="しぐれ">時雨</ruby></SUW> もしくは
<ruby rubyText="しぐれ"><SUW>時雨</SUW></ruby>
3a) <ruby rubyText="ケープタウン"><SUW>喜望</SUW><SUW>峰</SUW></ruby>
4a) <ruby rubyText="アール・ヌーヴォー"><SUW>新しい</SUW><SUW>芸術</SUW></ruby>
M-XMLでは、1a) 2a)のように、短単位タグの内側にrubyタグを置くことができる場合にはそのままとした。一方、3a) 4a) 5a)のように短単位を越えるルビについては、先頭の短単位をrubyタグで囲み、そのタグの属性値として本来のルビ範囲のテキストを保持することとした。これにより、元の状態に戻せるようにするとともに、複数単位に渡る特殊なルビを容易に取り出すことを可能にしている。
3a') <SUW><ruby rubyText="ケープタウン" rubyBase="喜望峰">喜望</ruby></SUW><SUW>峰</SUW>
4a') <SUW><ruby rubyText="アール・ヌーヴォー" rubyBase="新しい芸術">新しい</ruby></SUW> <SUW>芸術</SUW>
-
引用(quote)
次の例のように、短単位を分断する引用タグが現れる場合がある。
5) <quote>「解剖後厚く弔」</quote>うべしという指示
このような引用については、引用符のテキストを移動し、元の場所に空要素タグを残すことで対処した。
5') <quote>「解剖後厚く弔<move type="original" text="」"/>う<move type="modify"> 」</move></quote>べしという指示
新たに追加したタグ
M-XMLでは、SUW ・LUW以外にも次のようなタグが新たに追加されている。
A. 数字変換(NumTrans)
数字を解析しやすい表記に変換する処理(numTrans)を行った箇所に付けられている。変換前の本文はこのタグのoriginalText属性に保存されている。
B. 分数(fraction)
帯分数以外にも分数にfractionタグが追加されており、分子・分母が次のようにタグ付けされている。NumTrans処理もあわせて行われている。
<denominator><NumTrans originalText="45">四十五</NumTrans></denominator>
<vinculum><NumTrans originalText="/">分</NumTrans></vinculum>
<numerator>1</numerator>
</fraction>
C. 改ページ位置(info)
改ページ位置を示す参考情報が空要素のinfoタグに残されている。
以上のように、できる限り互換性を保持するように努めているものの、各種の変更を加えているため、M-XMLに付与されたタグとC-XMLのタグとの間に完全な互換性はない。