- Outline
How to Apply
-
BCCWJ Design
-
Paid Edition Contents
- Documents
-
Research Results
Data Sampling
Random Data Sampling
NINJAL has previously conducted surveys of lexical items based on random data sampling methods. Such methods have been used in the creation of more specific parent data sets, for example a set of published newspapers from the 1990s. Random data sampling is an extremely effective statistical method for producing data sets which accurately represent the properties of the parent set.
KOTONOHA's BCCWJ also makes use of a basic random sampling method for data gathering (although in some instances where it would serve to increase the corpus' representativeness of modern written Japanese, non-random sampling methods are also used). The sections below will describe with random data sampling methods used to extract the corpus data from the parent set of publications.
Treatment of the Parent Data Set
In order to implement a random data sampling process, it is necessary to carefully consider the parent data set in advance. For this purpose, it was decided to first determine exactly what a written word is. Although the written word can take many forms, in this case it was decided to only consider words that had been published in print form. Specifically, this includes books, newspapers, and magazines, all of which are written for a large number of readers, and hence can be thought of as public written language.
On the other hand, sources such as diaries and letters are excluded from the parent data set. Although there is certainly value to the Japanese found in these sources, but because it is not possible to know the degree of personal usage style contained in the works, they were not considered appropriate for inclusion in the parent set.
The scope of the newspapers and magazines to be included is also an issue. For newspapers, there is the question of whether to include only major national papers, or to also consider local publications, sports papers, and trade journals. There is no definitively correct answer to this issue - it is necessary to carefully consider the objectives of the corpus when deciding on the scope of the parent set.
Stratification of Data for Sampling
The next step is to segment each of the included media types (books, newspapers, magazines, etc.). For example, it is possible to stratify books based on their content using the Japanese Decimal Classification System (NDC) used in libraries.
For example, the total number of published words in different NDC categories are listed in the table below. When examining the table we can see that the "General" category makes up 3.37% of published data, while "Literature" makes up 19.25%. Based on such information it is possible to avoid accidental bias in the data sampling, and thus increase the precision of the parent data set.

Data for stratification purposes can be obtained from yearly publication journals and book information databases.
| NDC | Total Characters | Percentage |
|---|---|---|
| 0. General | 1,636,414,548 | 3.37% |
| 1. Philosophy | 2,597,610,813 | 5.35% |
| 2. History | 4,301,204,340 | 8.86% |
| 3. Sociology | 12,408,321,943 | 25.56% |
| 4. Natural Sciences | 5,069,594,034 | 10.44% |
| 5. Tech and Engineering | 4,615,929,967 | 9.51% |
| 6. Industrial | 2,196,387,437 | 4.53% |
| 7. Fine Arts | 3,258,432,447 | 6.71% |
| 8. Language | 888,800,128 | 1.83% |
| 9. Literature | 9,341,275,486 | 19.25% |
| n. No Record | 2,225,954,208 | 4.59% |
| Total | 48,539,925,351 | 100.0% |
Sample Selection
This section will explain exactly how samples are obtained. First, a page is randomly selected from a book. The figure below on the left is an example of one such page.

Next, the page is segmented, as in the image above on the right, and one of the hundred points of intersection is randomly chosen (as in the red arrow on the example image). Then, starting from the character nearest to the chosen point, a "Fixed length sample" (of 1,000 characters) is created. For this reason, sources such as advertisements, charts, photographs, and illustrations are outside the scope of the data sampling.
The sampling method for newspapers and magazines is also fundamentally the same. However, the formatting of printed type in newspapers and magazines is more complex than in books, so the precise counting of characters is more difficult than with books.
Sample Length (Fixed and Variable Length Samples)
As was discussed in the basic design issues section, the length of the samples changes based upon their intended use. In order to make the BCCWJ a more all-purpose corpus, both comparatively short samples, and longer samples taking context into consideration were included. The former are referred to as "Fixed Length" samples, while the latter are called "Variable Length" samples. Both the Publication sub-corpus and the Library sub-corpus contain these two types of samples concurrently.
Fixed Length Samples
These are samples using randomly extracted sets of 1,000 characters, not including punction marks or other symbols. The beginning and end of the samples may occur in the middle of sentences, but in order for the context to be clear samples will be extended to include complete sentences. Also, though they are not counted all punctuation marks and symbols are included. Because of the consistency of the sample sizes, these samples are appropriate for statistical analyses of word or character frequencies.
Variable Length Samples
These are randomly chosen samples of entire chapters or large sections of a source. As chapter and sections lengths are not fixed, both very short and very long samples exist. However, because overly long samples may introduce biases into the data, a length limit of 10,000 characters was established. These samples are suitable for discourse analysis and examination or literary structure.
Variable Parent Data Sets
The design of the parent data set discussed above makes use of statistics related to the publication (i.e. the Production-aspect) of written language, but that is not the sole possible means of creating a parent set. For example, one might also create a parent set based on the reception of the written language in question. There are many books in the world that are published, but end up mostly unread, and such lack of reception would have to be actively considered in a parent set based on the consumption of written language. However, as there is no simple way to calculate the consumption of printed works, such a parent set can not feasibly be created.
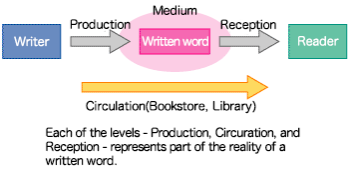
Between "Production" and "Reception", another stage - "Circulation" - exists; books on display in a bookstore or collected at a library can be thought of as in circulation. Although the distribution of books at bookstores is not available, there is data regarding public library collections which can be considered in the creation of the parent data set.
Thanks to the kindness of the central Tokyo Metropolitan Library, we were able to access data regarding the collections of libraries from 52 municipalities of Tokyo. In total there are 15.63 million volumes in all the collections, although this includes a large number of duplicates. When duplicates are excluded from the calculations, there are a total of 1.14 million volumes. It is possible to ascertain the actual demand for these books by examining their records - if a book was found in a number of collections, it seems fair to assume that there is demand for it based on that fact.
Exactly what level of circulation is desirable depends on ones objectives, but for the purposes of the parent data set based on a catalogue of publications, it was determined that books circulated at at least 13 libraries would be included in the parent set.
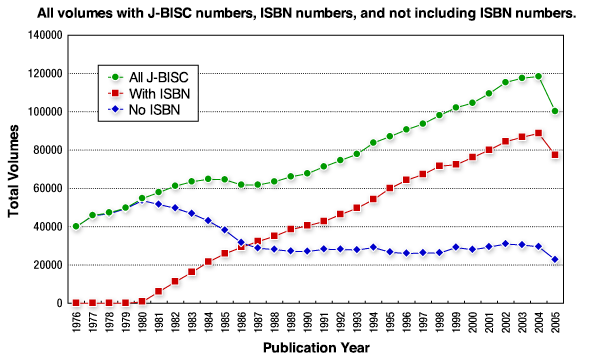
Sampling of the works from library collections was done based on the ISBN (Internation Standard Book Number) book Ids. However, in Japan ISBN was only adopted in 1981, and it took some time for its usage to spread.
The graph above gives a year-by-year breakdown of the volumes with J-BISC (Japanese book identification system) numbers in library collections which did and did not have corresponding ISBN numbers. The majority of books began to have ISBN numbers around 1987, and from that point there was a roughly constant proportion of sources without ISBN numbers, though these mainly consisted of government documents. Therefore, it was decided to make 1986 - where the distribution of ISBN numbers had become stable - the start point for the parent data set. In practical terms, by 1986 most major publication companies had adopted the use of ISBN.