- Outline
How to Apply
-
BCCWJ Design
-
Paid Edition Contents
- Documents
-
Research Results
M-XML (Integrated XML data) Details
The M-XML data can be found in the M-XML directory on Disc 1, divided into subdirectories for each sub-corpus. Each directory holds a compressed file, which when extracted contains a number of XML files, each corresponding to a single sample. XML files for registers with a particularly large number of samples (the LB, PB, OC, and OY registers) will be extracted into individual subdirectories.
M-XML (integrated XML) is a format based on the C-XML (character-based XML) format, which aims to provide an integrated, standardized description of the linguistic structure of both variable and fixed length samples. It embeds while maining information regarding the morphological analysis of short and long unit words, as well as hierarchical structure in order to simplify the handling of information related to linguistic structure. The XML files are encoded in UTF-8 format (without BOM).
Integration of Variable Length and Fixed Length
C-XML is structured to use separate XML documents for variable length and fixed length samples. However, as both types of samples are gathered from a single text, a large number of sample portions will be duplicates. In order remove the neccessity of embedding morphological analyses twice, an integrated method of treatment for such data is desirable. However, as the tags would conflict it is not a simple matter to integrate two XML formats containing different structures. Accordingly, it was decided to integrate variable length and fixed length samples into a new integrated format using the following methods.
To begin with, unlike the variable length samples which were made with document structure in mind, block element tags describing document structure do not hold great meaning for fixed length samples where the objective was to obtain samples of uniform length. For that reason, it was decided that M-XML should maintain only the document structure of variable length samples, while assigning morphological descriptions (for both long and short unit words) to the contents of fixed length samples. Cases where the fixed length section is taken from a variable length sample are marked by a simple container (<div type="fiexdLength">), maintaining only inline elements.
M-XML identifies elements as described above using the following "mergedSample" element as a root.
<mergedSample sampleID="サンプルID" type="BCCWJ-MorphXML" version="1.0">
Integration of Variable Document-Type-Definitions
In C-XML, different document type definitions are used dependent on the sub-corpus. While the Yahoo! Answers (OC), Blogs (OY), Textbook (OT), and Poetry (OV) registers all have mostly similar structures, they each vary from general variable length samples depending upon their particular document type definitions. Because of this, when processing the data into a unified form it is possible for problems to arise.
Therefore, M-XML modifies portions of the tag sets in order to allow for the processing of a unified document type definition for all sub-corpora. Although the constraints will necessarily be somewhat loose when compared to C-XML, all the XML files can be examined via a single XML scheme. For this integration, tags particular to certain sub-corpora have been partially modified as in the following example.
OC : <OCQuestion> → <article articleID="サンプルID-Question">
<OCAnswer> → <article articleID="サンプルID-Answer">
OC, OY: <br type='physicalLine_original /> → <webBr/>
OT : <root> → <squareRoot>
Hierarchical Structure of Morphological Information
The BCCWJ's layered structure is created based on the items defined as short unit words, long unit words, and clauses. As continuous clauses are make up sentences, and short unit words composed of characters, the morphological information contained in the BCCWJ uses the following hierarchical structure of lexical items.
Article / Sentence / Phrase / Long Unit Word / Short Unit Word / Character
In order to make practical use of the tags relating to document structure, and of the stratified morphological information, it is desirable for this hierarchical structure and its implied relationships to be reflected in the XML format. Based on this line of thinking, the morphological information is presented using the following structure.
The example below is a single sentence element extracted from a larger sample (for ease of reading, some properties have been omitted.)
<LUW B="B" SL="v" l_lemma="公共工事請け負い金額" l_lForm="コウキョウコウジウケオイキンガク" l_wType="混" l_pos="名詞-普通名詞-一般" >
<SUW lemma="公共" lForm="コウキョウ" wType="漢" pos="名詞-普通名詞-一般" pron="コーキョー">
公共
</SUW>
<SUW lemma="工事" lForm="コウジ" wType="漢" pos="名詞-普通名詞-サ変可能" pron="コージ">
工事
</SUW>
<SUW lemma="請け負い" lForm="ウケオイ" wType="和" pos="名詞-普通名詞-一般" pron="ウケオイ">
請負
</SUW>
<SUW lemma="金額" lForm="キンガク" wType="漢" pos="名詞-普通名詞-一般" pron="キンガク">
金額
</SUW>
</LUW>
<LUW SL="v" l_lemma="の" l_lForm="ノ" l_wType="和" l_pos="助詞-格助詞" >
<SUW lemma="の" lForm="ノ" wType="和" pos="助詞-格助詞" pron="ノ">の</SUW>
</LUW>
<LUW B="B" SL="v" l_lemma="動き" l_lForm="ウゴキ" l_wType="和" l_pos="名詞-普通名詞-一般" >
<SUW lemma="動き" lForm="ウゴキ" wType="和" pos="名詞-普通名詞-一般" pron="ウゴキ">
動き
</SUW>
</LUW>
(略)
</sentence>
Properties of Short Unit Word Tags
The following properties can be assigned to the embedded Short Unit Word tags (SUWs). * In cases where it is not necessary to output the properties of symbols, output will not occur for either the variable or the property itself.
| Property Name | Notes |
|---|---|
| start | Offset values from the heads of character strings in the original sample (in increments of 10). |
| end | |
| orderID | Serial # (compatible with TSV serial #s) |
| lemma | A lexeme |
| lForm | A lexeme's reading |
| subLemma | Lexical sub-type * Only outputted when there is a distinction. |
| wType | Word origin (e.g. native, borrowed, sino-Japanese) |
| pos | Part of speech |
| cType | Inflectional pattern * Only outputted for inflected words. |
| cForm | Inflected form * Only outputted for inflected words. |
| formBase | Word form |
| usage | Rules of use * Only outputted when there is a distinction. |
| orthBase | Infinitive form * Only outputted for inflected words. |
| originalText | Characters string appearing in the original text. * Only outputted in instances where there are differences from the element in the original text. |
| kanaToken | Kana form and surface form * Outputted only if there is a difference from the word form. |
| pronToken | Surface pronunciation. |
Additionally, the underlying and surface forms in the TSV files corresponds to the text contained by the SUW tags. The kana forms and surface forms correspond to the kana readings in the text (or to the kana character strings, in the case of IME input).
* Source: TSV data details.
Properties of Long Unit Word Tags
The following properties can be applied to embedded Long Unit Word (LUW) tags. * In cases where it is not necessary to output the properties of symbols, output will not occur for either the variable or the property itself.
| Property Name | Notes |
|---|---|
| B | Sentence or clause boundaries. Clause boundaries=B, Sentense boundaries=S. |
| SL | Sample length. Fixed length=f, Variable length=v |
| l_lemma | Lexeme |
| l_lForm | Lexeme reading |
| l_wType | Word type (e.g. native, borrowed, sino-Japanese) |
| l_pos | Part of speech. |
| l_cType | Inflectional pattern * Only outputted for inflected words. |
| l_cForm | Inflected form * Only outputted for inflected words. |
| l_formBase | Word form. |
| l_orthBase | Infinitive form * Only outputted for inflected words. |
Does not include information that can be obtained easily from the TSV "Long/Short agreement" data, the XML structure, or the properties of the subordinate SUWs.
Tags Modified from Character-based XML (C-XML)
If applying the hierarchy of morphological information described above to the various C-XML elements, the results can be thought of as in the "Hierarchical structure of included morphological information" table below (the colored elements are all parts indispensable to the original text). However, at such a time the problem arises of various elements from C-XML causing inconsistencies with this hierarchy. This is dealth with in M-XML by making the following changes to the C-XML tags.
Hierarchical Structure of Included Morphological Information
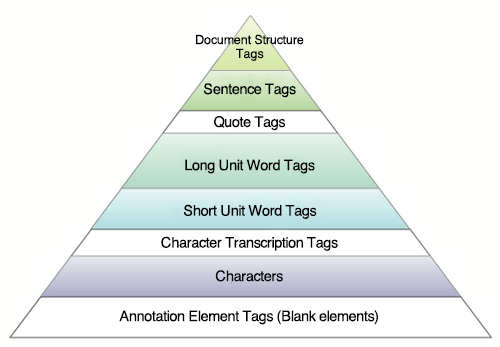
A. "sentence" Tags
In C-XML, it is allowed to have a large number of subordinate "sentence" tags, allowing as many sentences as necessary to be contained within a larger sentence. For example, in the following example where there is a quotation within a larger sentence, both the full sentence and the quotation are contained in "sentence" tags, with the quotation's "sentence" tag containing some markup information.
「<sentence>落ちた、落ちたって言わないでよ。</sentence>
<sentence type="quasi">結構辛がってるんだから</sentence>」</quote>
言って夕美子は目を伏せ、(中略)うつむいている。</sentence>
Although the mark-up information describing the complex nested sentence does have active meaning, problems do exist, such as: (1) The possibility for the top-level sentence to become excessively long, (2) The lack of clear rules governing the "Sentence" element when inputting morphological analysis, and (3) The inability to sort data via sentence number.
Therefore, in order to maintain the sentence hierarchy in M-XML, it was decided to no longer allow nested sentences as in the example above, and to instead to assign top-level sentences the new type of document structure tag, "superSentence". Subordinate sentences remain as they were, while a partial sentence directly following a "superSentence" tag will be marked with the new property type="fragment".
<sentence type="fragment">驚きながらそう誤魔化した構治の言葉に、</sentence>
<quote><sentence>「落ちた、落ちたって言わないでよ。</sentence>
<sentence type="quasi">結構辛がってるんだから」</sentence></quote>
<sentence type="fragment">言って夕美子は目を伏せ、(中略)うつむいている。</sentence>
</superSentence>
B. In-line Elements
As there is a possiblity of tags inserted inside a sentence causing conflicts with the morphological information, it will be dealt with in the following way
-
"rubi" (transcriptions)
While in the BCCWJ furigana transcriptions of kanji readings are typically assigned to all kanji, in cases where there are special or exceptional kanji readings, multi-character strings will be marked with the "rubi" tag, as in the following examples.
1) 語彙(い) (A transcription shorted than a SUW)
2) 時雨(しぐれ) (A transcription the same length as a SUW)
3) 喜(ケー)望(プタ)峰(ウン) (A transcription longer than an SUW)
4) 新しい(アール・)芸術(ヌーヴォー) (A transcription longer than a LUW)
This is example would be marked in C-XML as follows:
1a) <SUW>語<ruby rubyText="い">彙</ruby></SUW>
2a) <SUW><ruby rubyText="しぐれ">時雨</ruby></SUW> もしくは
<ruby rubyText="しぐれ"><SUW>時雨</SUW></ruby>
3a) <ruby rubyText="ケープタウン"><SUW>喜望</SUW><SUW>峰</SUW></ruby>
4a) <ruby rubyText="アール・ヌーヴォー"><SUW>新しい</SUW><SUW>芸術</SUW></ruby>
In M-XML, examples such as 1a) and 2a) where "ruby" tags are contained within "SUW" tags are left as-is. On the other hand, in examples such as 3a, 4a, and 5a where the scope of the "ruby" tag covers the head of an "SUW", it was decided, in order to indicate the true scope of the "ruby" tags, to contain the "ruby" tags within "SUW" tags while maintaining the original text of the "ruby" tag as a tag property. Thus, is becomes possible to revert to the original state, allowing for simple extraction of a special "ruby" tag across multiple units.
3a') <SUW><ruby rubyText="ケープタウン" rubyBase="喜望峰">喜望</ruby></SUW><SUW>峰</SUW>
4a') <SUW><ruby rubyText="アール・ヌーヴォー" rubyBase="新しい芸術">新しい</ruby></SUW> <SUW>芸術</SUW>
-
Quotations ("quote" tag)
There are cases where an SUW is broken up by a quotation tag, as in the following example.
5) <quote>「解剖後厚く弔」</quote>うべしという指示
このような引用については、引用符のテキストを移動し、元の場所に空要素タグを残すことで対処した。
5') <quote>「解剖後厚く弔<move type="original" text="」"/>う<move type="modify"> 」</move></quote>べしという指示
Supplemental Tags
In addition to the SUW and LUW tags, the following supplemental tags have been created for M-XML.
A. Numerical Conversion ("NumTrans")
There are portions of the text wherein numerical transcriptions have been modified after undergoing the NumTrans process. The original text is retained in the "originalText" property of this tag.
B. Fractions ("fraction")
The "fraction" has been added to mark fractions (outside of compound numbers) - numerators and denominators are marked in the following fashion. The "NumTrans" process is also occurs together with fractions.
<denominator><NumTrans originalText="45">四十五</NumTrans></denominator>
<vinculum><NumTrans originalText="/">分</NumTrans></vinculum>
<numerator>1</numerator>
</fraction>
C. Pagination ("info")
Any reference information regarding revised pagination is left in the "info" tag element. Although all efforts have been made to maintain compatibility as shown above, due to the large number of changes there is no perfect way to maintain compatibility between the appended M-XML tags and C-XML tags.