- Outline
How to Apply
-
BCCWJ Design
-
Paid Edition Contents
- Documents
-
Research Results
XML Document Structure
It is possible to look up a large amount of data regarding the texts collected in the BCCWJ, as illustrated below.
Bibliographical Information
Citation information (Title, Author Name, Publishing Company, Publication Year, Genre)Japanese character information
Character readings, misprints, JIS encoding, calculation superscripting, subscript informationStructure Information
Information regarding the layered structure of the text (article, paragraph, sentence, captions, quotations, itemized lists, etc.)Data Sampling Information
Information about the scope of Fixed-length samples.
Description of XML
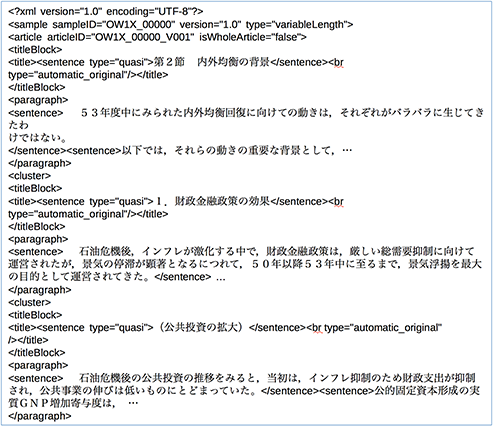
The above information is compiled using XML markup. For example, take the following text:

The above text will then be digitized as in the following example. The sections enclosed in < > are called tags. What type of tags are available and how they are organized has a large influence on how information can be accessed in the corpus.
Tag Types and Meanings
This section will explain the tags used in the BCCWJ.
| Tag Name | Contents | |
|---|---|---|
| Samples | sample | The scope of a single sample. |
| sampling | Information related to the sampling points. | |
| Layered Structure (Document Structure) |
article | Identifies author and theme. |
| title | Gives a title descriptive of the contents, such as a chapter or article title. | |
| cluster | Marks the whole text of a title tag. | |
| list | Itemized lists or lists of noun phrases. For list elements. | |
| paragraph | Marks the boundaries of paragraphs. | |
| sentence | Marks sentence boundaries. | |
| Charts
(Document Structure) |
figure | Figures・Charts・Photos・Pictures, and others |
| caption | Titles and explanations of figures. | |
| Citations (Document Structure) |
citation | Any citations of other documents. |
| speech | Speech and internal monologues, opening sentences. | |
| Annotation (Document Structure) |
noteBody | Footnotes, endnotes, etc. An element describing or annotating the original text. |
| Other (Document Structure) |
abstract | Outlines that do not fit under the article or cluster tags. |
| verse | Verses of poems、waka、haiku、songs, etc. | |
| Characters and Transcription | ruby | Readings of Kanji characters |
| correction | Corrections of mistakes in the original text. | |
| missingCharacter | Characters not included in the standard encoding (non-JIS). |
Character Encoding
Digitized texts are encoded using the JISX0213:2004 standard (aka JIS 4th edition), a type of Unicode encoding.