- Outline
How to Apply
-
BCCWJ Design
-
Paid Edition Contents
- Documents
-
Research Results
[Important] Notice of Corpus Name Change
The National Institute for Japanese Language and Linguistics (NINJAL) is currently developing the "Balanced Corpus of Contemporary Written Japanese, Part 2" (BCCWJ2) as an extension of the "Balanced Corpus of Contemporary Written Japanese" (BCCWJ).
As part of this project, the corpus that has previously been released as the "Balanced Corpus of Contemporary Written Japanese" (BCCWJ) has been renamed the "Balanced Corpus of Contemporary Written Japanese, Part 1" (BCCWJ1).
This page provides information on the "Balanced Corpus of Contemporary Written Japanese, Part 1" (BCCWJ1). Information on the "Balanced Corpus of Contemporary Written Japanese, Part 2" (BCCWJ2) is provided separately and is not included on this page.
Basic Design Policy
The Necessity of a Balanced Corpus
When considering Japanese corpora post year-2000, one point that stands out is the lack of a well balanced corpus covering all aspects of the language.
For example, many newspaper companies make databases of their old articles publically available, and those archives contain several hundred million words. However, even if your focus is solely on written Japanese, such a corpus will still not allow for a good grasp of all of written Japanese; the Japanese found in magazine articles is clearly different from that of newspapers, and literary works go without saying. Regarding literary works such as novels, the "Aozora Bunko" digital library has made a great effort to make it possible for numerous works to become available for public use. However, because all such works must be in the public domain, it can only give examples of Japanese from before the 1950s.
To summarize the above, when looking for a corpus for linguistic study of the Japanese language, existing corpora have the following problems:
- There is a bias towards the analysis of familiar sources such as digitized newspapers and literary works.
- Such sources represent only a part of written Japanese, and it is not clear exactly what aspects of the language they are missing.
- Therefore, it is difficult to know for sure how valid and applicable information gained from such sources actually is.
- Because the materials are not all available to the public, and there has been no 3rd party inspection results are difficult to reproduce.
Basic Design Policy for a Balanced Corpus
To address these problems, a corpus following the design principles below was designed.
- The aim should be to create a corpus which is an accurate microcosm of the state of the Japanese language, a so-called Balanced Corpus. For that purpose, statistically random sampling will be conducted from a parent data set.
- As this will be a microcosm of modern Japanese, the parent set must not be too narrow. In the surveys of lexical sources up to now, NINJAL has dealt with such sources as newspapers, magazines, and middle/high school text books, but now in addition to those more general publications will be added - foremost publications drawn from internet sources - and must all be subsumed into a single parent set representing the totality of modern written Japanese.
- Even if the corpus is created, if it is not publically available then it serves little purpose. The copyright process must be dealt with in order for it to be a public corpus.
- Up to now NINJAL has strived to maintain publically available and compatible corpora. Therefore, we will aim to make it compatible with the analytical framework used in the previously publically released corpus, the "Corpus of Spontaneous Japanese".
Issues Concerning the Design of an All-Purpose Corpus
In creating a general-purpose corpus, a few potential problems are created.
Based upon the objectives of the corpus, the methods of sampling will necessarily change. In NINJAL's previous examinations of lexical items, it was appropriate to pull from smaller samples of a few dozen words, but in order for the corpus to be used for discourse analysis and semantic factoring it is important to be able to understand context, and so a much larger sample - of thousands of words - is desirable.
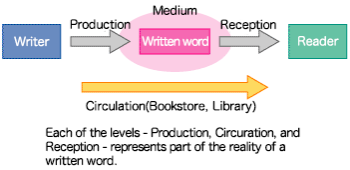
Deciding what exactly is representative of the "Reality" of modern Japanese is also a potential problem. This is because, as illustrated in the figure below, there are three possible phases of the existence of a written word which can be focused upon - the "Production", the "Circulation" and the "Reception". Each of these processes hold meaning when considering the reality of a written word.
Among those phases, there is existing data on the use of "Production" and "Circulation" in the creation of samples. However, there is little such pertinent data on the usage of the "Reception" mechanism, and because of the prohibitively large amount of labor involved in conduction a large-scale survey to acquire it, no such data on the influence of the "Reception" mechanism will be available.
Organization of the BCCWJ
In order to attempt to resolve the previously mentioned issues in some way, three sub-corpora with differing properties were constructed. These are the Publication, Library, and Special-Purpose sub-corpora. Each sub-corpus is designed to reflect a different aspect of written Japanese - the Library sub-corpus is focused on the production aspect, the Library sub-corpus on the circulation aspect. The Special-purpose sub-corpus texts such as web documents, and other texts which do not fall under the purview of the other two sub-corpor, with the objective of being of use for specialized research.
As mentioned above, due to the untenable amount of time required, no sub-corpus was constructed which is reflective of the "Reception" aspect of written language. The figure below outlines the details of the three sub-corpora.

Three Types of Sub-Corpora
Publication (Production-focused) Sub-Corpus
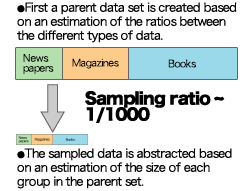
The green, top-left section of the figure above gives details of the Publication sub-corpus. The parent data set was created based on a catalogue of publications, and from that a random sampling of data was complied. The sub-corpus aims to give a representative cross-section of published written Japanese.
- The sub-corpus consists of around 35 million words.
- The focus is on books, newspapers, and magazines.
- Individual samples are grouped by length - fixed length samples (of 1000 characters) and variable length (up to 10,000 characters).
- The dates of the included works range from 2001-2005.
Regarding sampling, estimations were made of the total amount of words published in a set period (for example, over one year), and samples were taken based on the ratio of total published words in each type of work over the period. In order to estimate the amounts of words, different methods were used: for newspapers, pages were arbitrarily selected over a period of a week and the characters they contained were counted, and the total amount published over a year was extrapolated from that number. For books, the average number of words per page was calculated based on examples from the National Diet Library catalogue, and then extrapolated to a total number of words published over the period.
Library (circulation-based) Sub-Corpus
The purple section in the top-right of the figure above gives information on the Library sub-corpus. The sub-corpus is not focused solely on published works, but rather on texts which have been confirmed to be in wide circulation. With the cooperation of the Tokyo Public Libraries, a parent data set has been created from their collections, and a random sample of that set was taken. This sub-corpus is therefore focused on the 'circulation' aspect of written language.
- The sub-corpus contains roughly 30 million words.
- The objective is to compile examples of books.
- There are two types of samples - fixed length (1,000 characters) and variable length (up to 10,000 characters).
- The dates of the included works range from 1986-2005.
The parent data set of the Library sub-corpus complements the related section of the parent set from the Publication sub-corpus (containing books), allowing for expanded sampling at roughly similar ratios; the section of the Publication sub-corpus relating to books contains a total of roughly 48.54 billion characters, and the total number of characters contained in the circulated volumes of the libraries of Tokyo's 13 municipalities is quite close, totalling 47.88 billion.
Special-purpose Sub-Corpus
The grey section at the bottom of the above figure relates to the special-purpose sub-corpus, containing other parts of the parent data set. This sub-corpus contains data which, while very important to Japanese, is difficult to fit in the two previous sub-corpora, and data which is of importance for addressing linguistic issues researched at NINJAL.
- The sub-corpus contains roughly 35 million words.
- Contains examples of books, PR documents, and web posts, among others.
- Individual samples are of variable length (up to 10,000 characters) while some individual documents are of fixed length (1,000 characters) or variable length.
- The dates of the included texts range from 1976-2005.
- There are instances where the sampling is not random.
More specifically, the sub-corpus contains the following types of data: Bestsellers, business reports, authorized textbooks, PR documents, web postings (from Yahoo answers), blogs (from Yahoo! Blogs), poetry, legal documents, and minutes of the national diet.
The Copyright Process and Care of Personal Information
The BCCWJ seeks to represent the original texts as accurately as possible, but due to personal information protection laws, any portions of text which might reveal personal information will be hidden. There are also instances where entire samples were necessarily excluded.
If we receive requests from copyright holders to withhold portions of texts, the request will be granted regardless of whether or not the section would violate personal information protection laws. For example, on request from a newspaper, we would remove the actual names of "Suspects" or "Victims" from a newspaper article.