CSJ-RDB Version2.0 の構成
CSJ-RDBは、次の3種類のデータベースから構成されています。
基本データベース(csj.db)
基本データベースは、次の5種類のテーブルから構成されています。
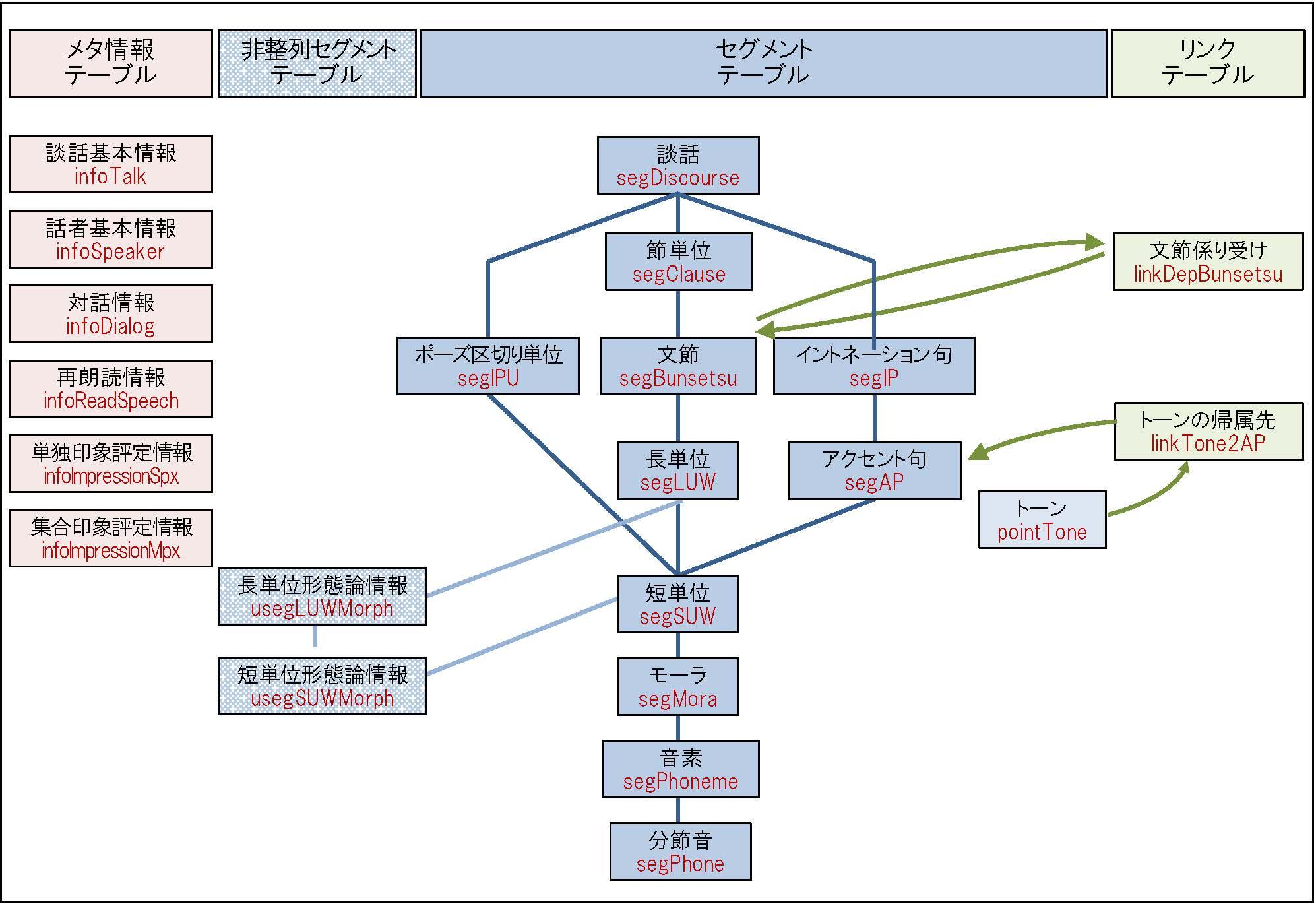
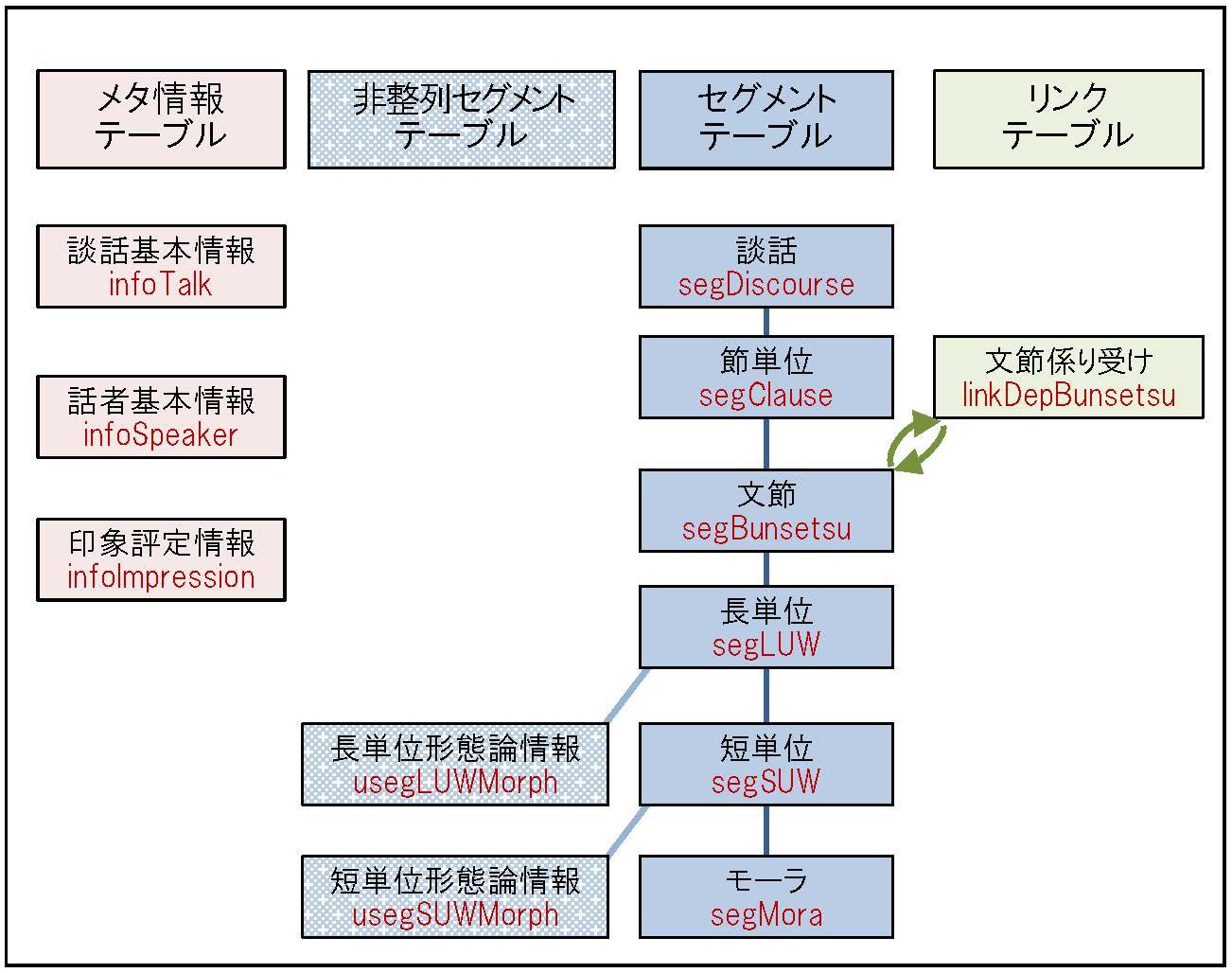
セグメント・テーブル
セグメント・テーブルは、図1の各単位ごとに、談話中の要素を記述したテーブルです。すべてのセグメント・テーブルに共通する情報として以下があります。
| 列名 | 説明 | 例 |
|---|---|---|
| TalkID | ファイルID | A01F0055 |
| ClauseID、BunsetsuID、SUWID など | 各単位のID | 00720909L |
| StartTime | 単位の開始時間 | 720.909 |
| EndTime | 単位の終了時間 | 721.369 |
| Channel | 話者ラベル | L |
これらによって、各単位の生起位置を一意に特定することができます。特別な場合として、トーン情報(アクセントや句末の音調などの韻律情報)のように、ある瞬間に生起する(開始時間と終了時間が等しい)ものもあります。これらをポイント・テーブルと呼びます。ポイント・テーブルは次の情報で表現されます。
| 列名 | 説明 | 例 |
|---|---|---|
| TalkID | ファイルID | A01F0055 |
| ToneID | 各要素のID | 00720909L |
| Time | 要素の生起時間 | 720.909 |
| Channel | 話者ラベル | L |
以上の共通情報に加えて、各単位・要素に固有の情報が記されています。各テーブルの個別情報の一覧と各単位・要素のIDは以下をご覧ください。
参照:
非整列セグメント・テーブル
自発音声では、複数の語が融合して、分割できない一つの要素を形成することがしばしば生じます。「僕は」が融合して「ボカー」と発音されるような場合です。ここで、形態論情報(短単位・長単位)としては、「僕」と「は」の2つの要素に分けて記述されますが、融合して発音されているため、「僕」と「は」の境界の時間を特定することができません。
そこで基本データベースでは、単語(長単位と短単位)のうち、時間的に分節化できる部分をセグメント・テーブルで表し、時間的に分節化できない部分は、その下位にある非整列セグメントで表現しています。セグメント・テーブルには、開始・終了時間が特定できますが、「ボカー」のような単位も含まれるため、品詞などの情報は付きません。一方、非整列セグメント・テーブルは「僕」「は」のように分割されるため品詞などの情報を含みますが、開始・終了時刻を持ちません。
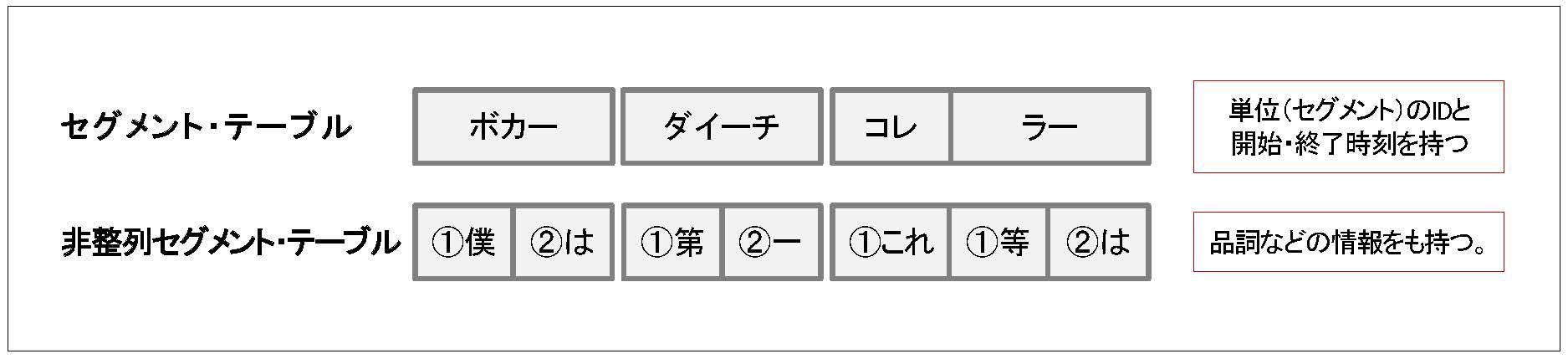
非整列セグメント・テーブルは、次の2つの属性を共通に持ちます。
| 列名 | 説明 | 例 |
|---|---|---|
| TalkID | ファイルID | A01F0055 |
| SUWMorphID、 LUWMorphID | 非整列セグメントがの各要素のID | 00720909L |
これらの共通情報に加えて、各単位に固有の情報が記されています。以下に各テーブルの個別情報を挙げます。
参照:
親子関係テーブル
親子関係テーブルとは、図1 に表された階層関係に従って、単位間の親子関係をID の対で表現したものです。例えば、図3のように、セグメント・テーブルとして「節単位テーブル」とそれに対応する「文節テーブル」があるとします。節単位と文節は親(先祖)と子(子孫)の関係にあるため、両者の間の対応関係を表現した親子関係テーブルが提供されます。
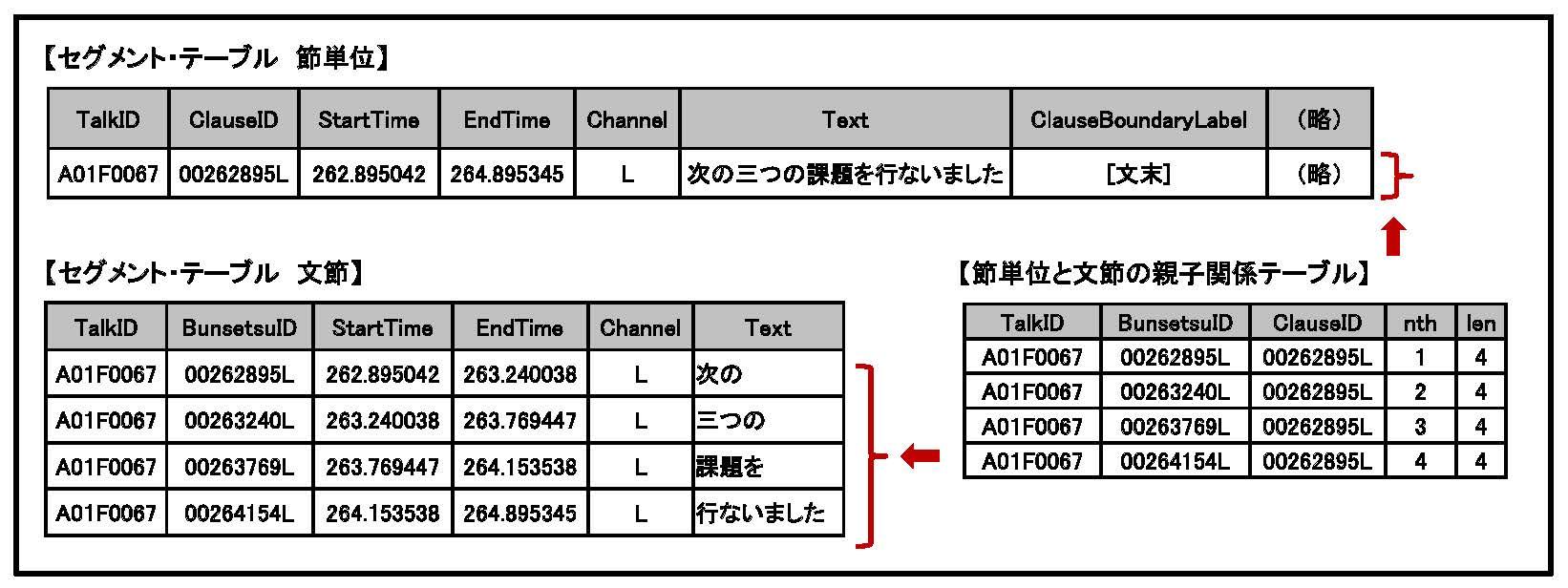
親子関係テーブルには、図3にある通り、以下の情報が共通して記されています。
| 列名 | 説明 | 例 |
|---|---|---|
| TalkID | ファイルID | A01F0055 |
| ClauseID、BunsetsuID、SUWID など | 親(先祖)セグメントのID | 00262895L(図3では親である節単位のID) |
| ClauseID、BunsetsuID、SUWID など | 子(子孫)セグメントのID | 00263769L(図3では子である文節のID) |
| len | 親セグメント中の子セグメントの総数 | 4(4つの子単位からなる親単位の場合) |
| ntd | 親セグメント中の子セグメントの位置 | 3(冒頭から3番目の場合) |
節単位と短単位も先祖と子孫の関係にあるので、同様のテーブルが作成されます。一方、節単位とアクセント句は親子関係にないため、この種のテーブルは作成されません(図1参照)。
親子関係テーブルを用いることによって、複数の単位に関わる分析を容易に行うことができます。例えば、節単位の最後の文節の継続長を取り出したり、10個以上の文節から構成される節単位を取り出す、といった検索ができます。他の単位間の親子関係も同様に記述されているため、例えば節単位の最後の文節の冒頭の短単位が接頭辞のものを抽出する、といった検索もできます。
リンク・テーブル
単位間の関係としては、親子関係以外にも様々なものが考えられます。例えば、文節係り受けは、文節同士の間の関係です。
基本データベースでは、このような親子関係以外の単位間の関係をリンク・テーブルで表現しています。リンク・テーブルとしては、「文節係り受け関係」と「トーンの帰属先」の2つがあります。後者は、韻律ラベルで与えられているアクセントや句末の音調などのトーンがどのアクセント句に帰属するかを表わしたものです。
リンク・テーブルには、以下の情報が記されています。
| 列名 | 説明 | 例 |
|---|---|---|
| TalkID | ファイルID | A01F0055 |
| リンク元となる文節のBunsetsuIDなど | リンク元セグメントのID | 00358705L |
| リンク先となる文節のBunsetsuIDなど | リンク先セグメントのID | 00359291L |
リンク元/先IDの名称はテーブルごとに異なります。以下に各リンク・テーブルの情報を挙げます。
参照:
メタ情報テーブル
メタ情報テーブルには、談話の基本情報を納めた「談話基本情報」、話者に関する情報を納めた「話者基本情報」、対話(インタビュー)の話題の元となった談話のIDやインタビュアーの情報を納めた「対話情報」、再朗読の読み上げ対象となった談話のIDや再朗読固有の印象評定値を納めた「再朗読情報」、個々の談話の各種印象情報を納めた「単独印象評定情報」と「集合印象評定情報」があります。以下に各テーブルの個別情報を挙げます。
参照:
テーブル情報詳細
セグメント・テーブル
- ■ 談話
- 列名
- 説明
- 例
- segDiscourse
- (独自の列なし)
- ■ 節単位

-
参照:
『日本語話し言葉コーパスの構築法』
第5章 節単位情報
-
- 列名
- 説明
- 例
- segClause
- Text
- テキスト
- そこに行きましたが
- ClauseBoundaryLabel
-
参照:
『日本語話し言葉コーパスの構築法』
第5章 節単位情報
5.2.3 CBAP-csjが検出する節境界の種類 p.267-269
図5.5 CBAP-csjで検出される49種類の節境界ラベル p.267
-
- 節境界ラベル
- /並列節ガ/
- CU_ObligateComment
-
参照:
『日本語話し言葉コーパスの構築法』
第5章 節単位情報
5.4.2 人手修正作業で扱う項目の分類 p.293-294
図5.11 人手修正の対象となる項目の一覧と,コア177講演における出現数 p.294
-
- 節単位義務的コメント
- 引用節構造
- ■ 文節
-
参照:
『日本語話し言葉コーパスの構築法』
第2章 転記テキスト
2.8 文節の認定基準 p.118-130
-
- 列名
- 説明
- 例
- segBunsetsu
- Text
- テキスト
- 国立国語研究所では
- ■ 長単位
-
参照:
『日本語話し言葉コーパスの構築法』
第4章 短単位・長単位データベース
-
- 列名
- 説明
- 例
- segLUW
- Text
- テキスト
- 国立国語研究所
- ■ 短単位
-
参照:
『日本語話し言葉コーパスの構築法』
第4章 短単位・長単位データベース
-
- 列名
- 説明
- 例
- segSUW
- Text
- テキスト
- 国語
- word
- 音素記号列
- kokugo
- ■ IPU
-
参照:
『日本語話し言葉コーパスの構築法』
第2章 転記テキスト
2.2 転記基本単位の認定 p.32-37
-
- 列名
- 説明
- 例
- segIPU
- Text
- テキスト
- 聞き分けに着目して
- ■ イントネーション句
-
参照:
『日本語話し言葉コーパスの構築法』
第7章 韻律情報
-
- 列名
- 説明
- 例
- segIP
- Text
- テキスト
- 聞き分けに
- Break
- Break Index (BI)
- 3
- FBT
- 句末境界音調
- HL%
- ■ アクセント句
-
参照:
『日本語話し言葉コーパスの構築法』
第7章 韻律情報
-
- 列名
- 説明
- 例
- segAP
- Text
- テキスト
- これが
- Break
-
参照:
『日本語話し言葉コーパスの構築法』
第7章 韻律情報
7.1.4 BI層 p.356-359
表7.6 X-JToBIのBIラベル(その1:中間値) p.356
表7.7 X-JToBIのBIラベル(その2:非流暢性など) p.357
7.2.2 BI層 p.409-429
-
- Break Index (BI)
- 2+bp
- FBT
-
参照:
『日本語話し言葉コーパスの構築法』
第7章 韻律情報
7.1.3.4 句末境界音調 p.354-355
表7.5 句末境界音調のラべリングに使用されるラベル p.354
7.2.1 トーン層 p.367-409
-
- 句末境界音調
- HL%
- Prm
-
参照:
『日本語話し言葉コーパスの構築法』
第7章 韻律情報
7.1.6 プロミネンス層 p.359-362
表7.8 X-JToBIのプロミネンスラベル p.360
7.2.4 プロミネンス層 p.430-431
-
- プロミネンス
- PNLP
- Misc
-
参照:
『日本語話し言葉コーパスの構築法』
第7章 韻律情報
7.1.7 注釈層 p.362-364
表7.9 X-JToBIの注釈ラベル p.362
7.2.5 注釈層 p.432
-
- 注釈情報
- AYOR
- ■ モーラ
-
参照:
『日本語話し言葉コーパスの構築法』
第6章 分節音情報
-
- 列名
- 説明
- 例
- segMora
- MoraEntity
-
参照:
『日本語話し言葉コーパスの構築法』
第6章 分節音情報
[付録6.1] 現代日本語のモーラとCSJ分節音ラベルの対応 p.343
-
- モーラ記号
- ユ
- PerceivedAcc
-
参照:
『日本語話し言葉コーパスの構築法』
第7章 韻律情報
7.1.5 単語層 p.359
7.2.3.2 アクセントラベル p.430
-
- アクセント核の有無
- 1(有)/0(無)
- ■ 音素
-
参照:
『日本語話し言葉コーパスの構築法』
第6章 分節音情報
-
- 列名
- 説明
- 例
- segPhoneme
- PhonemeEntity
- 音素記号
- Kj
- ■ 分節音
-
参照:
『日本語話し言葉コーパスの構築法』
第6章 分節音情報
-
- 列名
- 説明
- 例
- segPhone
- PhoneEntity
-
参照:
『日本語話し言葉コーパスの構築法』
第8章 XML文書
8.3.2.11 Phone要素 p.475-476
---------------------
分節音を記述する。分節音の記述に用いる記号については 6.2 節参照。なお,分節音補助ラベルで用いる "<", ">" は XML において特殊な意味を持つため,代わりに"S"を用いることにする。例えば"<cl>" は "SclS" と表現する。
---------------------
第6章 分節音情報
6.2 分節音ラベル p.323-325
-
- 分節音記号
- kj
- PhoneClass
-
参照:
『日本語話し言葉コーパスの構築法』
第8章 XML文書
8.3.2.11 Phone要素 p.475-476
第6章 分節音情報
6.2 分節音ラベル p.323-325
-
- 分節音記号のクラス
- Consonant
- Devoiced
-
参照:
『日本語話し言葉コーパスの構築法』
第8章 XML文書 8.3.2.11 Phone要素 p.476
---------------------
母音の無声化の有無を記述する。母音の無声化については 6.2 節および 6.7.7.3 節参照。
---------------------
第6章 分節音情報 6.2 分節音ラベル p.323
第6章 分節音情報 6.7.7.3 母音無性化に関わる問題 p.342
-
- 無声化の有無
- 1(有)/0(無)
- StartTimeUncertain
-
参照:
『日本語話し言葉コーパスの構築法』
第8章 XML文書 8.3.2.11 Phone要素 p.476
第8章 XML文書 8.3.3.1 分節音ラベルの融合 p.480
---------------------
分節音の開始・終了時刻の不明確さを記述する。分節音ラベリングにおいて融合した形で付与されたラベルについて,そのラベルが示す時間区間をラベル数で等分割する形で各ラベルの開始・終了時刻を決定し,PhoneStartTime, PhoneEndTime 属性に記述する。例えば StartTimeUncertain 属性を持つ Phone 要素で表される分節音は,前の Phone 要素で表される分節音と融合したラベルにより記述されていたことがわかる。分節音ラベルの融合については 8.3.3.1 節および 6.4.1 節参照。
---------------------
第6章 分節音情報 6.4.1 ラベルの融合 p.329
-
- 開始位置不明確
- 1(不明確)/0(明確)
- EndTimeUncertain
-
参照:
『日本語話し言葉コーパスの構築法』
第8章 XML文書 8.3.2.11 Phone要素 p.476
第8章 XML文書 8.3.3.1 分節音ラベルの融合 p.480
---------------------
分節音の開始・終了時刻の不明確さを記述する。分節音ラベリングにおいて融合した形で付与されたラベルについて,そのラベルが示す時間区間をラベル数で等分割する形で各ラベルの開始・終了時刻を決定し,PhoneStartTime, PhoneEndTime 属性に記述する。例えば StartTimeUncertain 属性を持つ Phone 要素で表される分節音は,前の Phone 要素で表される分節音と融合したラベルにより記述されていたことがわかる。分節音ラベルの融合については 8.3.3.1 節および 6.4.1 節参照。
---------------------
第6章 分節音情報 6.4.1 ラベルの融合 p.329
-
- 終了位置不明確
- 1(不明確)/0(明確)
- ■ トーン
-
参照:
『日本語話し言葉コーパスの構築法』
第7章 韻律情報
-
- 列名
- 説明
- 例
- pointTone
- toneLabel
- トーンラベル
- %L
- F0Uncertain
-
参照:
『日本語話し言葉コーパスの構築法』
第8章 XML文書 8.3.2.14 XJToBILabelTone要素 p.478
---------------------
XJToBILabelTone 要素が表すトーンラベルの付与位置において F0(基本周波数) が不明確であることを示す"x"の有無を記述する。トーンラベルにおける"x"については7.2.1.13節参照。
---------------------
第7章 韻律情報 7.1.3,7.2.1.13 x:補助記号(F0値が信頼できない) p.402
-
- F0の不明確さ
- 1(不明確)/0(明確)
■ 非整列セグメント・テーブル
- ■ 短単位
-
参照:
『日本語話し言葉コーパスの構築法』
第3章 形態論情報
-
- 列名
- 説明
- 例
- usegSUWMorph
- OrthographicTranscription
- 出現形(短単位)
- (M 行き)
- PlainOrthographicUlanscription
- タグ無し出現形(短単位)
- 行き
- SUWDictionaryForm
- 代表形(短単位)
- イク
- SUWLemma
- 代表表記(短単位)
- 行く
- PhoneticUlanscription
- 発音形(短単位)
- イキ
- SUWPOS
- 品詞(短単位)
- 動詞
- SUWConjugateType
- 活用の種類2(短単位)
- カ行五段2
- SUWConjugateForm
- 活用形2(短単位)
- 連用形2
- SUWMiscPOSInfo1
- その他情報1(短単位)
- 副助詞
- SUWMiscPOSInfo2
- その他情報2(短単位)
- 語幹
- SUWMiscPOSInfo3
- その他情報3(短単位)
- 言いよどみ
- ClauseBoundaryLabel
-
参照:
『日本語話し言葉コーパスの構築法』
第5章 節単位情報
5.2.3 CBAP-csjが検出する節境界の種類 p.267-269
図5.5 CBAP-csjで検出される49種類の節境界ラベル p.267
-
- 節境界ラベル
- <テ節>
- CU_preBracket
-
参照:
『日本語話し言葉コーパスの構築法』
第5章 節単位情報
5.4.1 人手修正作業の概要 p.292-293
表5.4 人手修正操作記号の一覧 「範囲記号」のうち開き括弧 p.293
-
- 節単位前ブラケット
- <<
- CU_postBracket
-
参照:
『日本語話し言葉コーパスの構築法』
第5章 節単位情報
5.4.1 人手修正作業の概要 p.292-293
表5.4 人手修正操作記号の一覧 「範囲記号」のうち閉じ括弧 p.293
-
- 節単位後ブラケット
- >>
- CU_OperationSign
-
参照:
『日本語話し言葉コーパスの構築法』
第5章 節単位情報
5.4.1 人手修正作業の概要 p.292-293
表5.4 人手修正操作記号の一覧 「切断記号」「結合記号」 p.293
-
- 節単位操作記号
- -
- CU_ObligateComment
-
参照:
『日本語話し言葉コーパスの構築法』
第5章 節単位情報
5.4.2 人手修正作業で扱う項目の分類 p.293-p.294
図5.11 人手修正の対象となる項目の一覧と,コア177講演における出現数 p.294
-
- 節単位義務的コメント
- 体言止め
- ■ 長単位
-
参照:
『日本語話し言葉コーパスの構築法』
第3章 形態論情報
-
- 列名
- 説明
- 例
- usegLUWMorph
- LUWDictionaryForm
- 代表形(長単位)
- イク
- LUWLemma
- 代表表記(長単位)
- 行く
- LUWPOS
- 品詞(長単位)
- 動詞
- LUWConjugateType
- 活用の種類(長単位)
- カ行五段
- LUWConjugateForm
- 活用形(長単位)
- 連用形
- LUWMiscPOSInfo1
- その他情報1(長単位)
- 格助詞
- LUWMiscPOSInfo2
- その他情報2(長単位)
- 促音便
- LUWMiscPOSInfo3
- その他情報3(長単位)
- 連語
■ リンク・テーブル
- ■ 文節係り受け
-
参照:
『日本語話し言葉コーパス』における係り受け構造付与
『日本語話し言葉コーパス』DVD付属マニュアル
-
- 列名
- 説明
- 例
- linkDepBunsetsu
- TalkID
- ファイルID
- S01F0001
- BunsetsuID
- 係り文節ID
- 00000676L
- ModifieeBunsetsuID
- 受け文節ID
- 00001131L
- Dep_Label
- 係り受けラベル
- D
- Dep_ObligateComment
- 係り受け義務的コメント
- F
- ■ トーンの帰属先
-
参照:
『日本語話し言葉コーパスの構築法』
第7章 韻律情報
7.1.3 トーン層 p.351-356
-
- 列名
- 説明
- 例
- linkTone2AP
- TalkID
- ファイルID
- S01F0001
- ToneID
- トーンID
- 3
- APID
- 帰属先アクセント句ID
- 00005551L
■ メタ情報テーブル
- ■ 談話基本情報
-
参照:
音声収録作業の概要
『日本語話し言葉コーパス』DVD付属マニュアル
音声収録作業の概要
記録票データ・対話記録票データ・講演者属性データ・ 対話参加講演者の講演一覧の解説
記録票データ・対話記録票データ・講演者属性データ・ 対話参加講演者の講演一覧の解説
-
- 列名
- 説明
- 例
- infoTalk
- TalkID
- ファイルID
- A11M0469
- TalkType
- 談話タイプ
- monolog/dialog
- Genre
- ジャンル
- 学会/課題/模擬/朗読
- SpeakerID
- 話者ID
- 116
- NumAudience
- 聴き手人数
- 50
- Topic
- 学会種・模擬講演のテーマ等
- 工学系学会1(音声関係)
- Style
- 学会における講演形式
- 通常の発表
- Device
- 講演使用器材・配布資料
- OHP・スライドの類
- SpeechPreparation
- 講演の準備
- 原稿
- SpeechSkill
- 講演の得手・不得手
- 得意
- TalkExperience
- 講演経験
- 10(年)
- EducationBackground
- 最終学歴
- 学部卒
- SpeakerAge
- 収録時の年齢
- 35to39
- ■ 話者基本情報
-
参照:
記録票データ・対話記録票データ・講演者属性データ・ 対話参加講演者の講演一覧の解説
『日本語話し言葉コーパス』DVD付属マニュアル
-
- 列名
- 説明
- 例
- infoSpeaker
- SpeakerID
- 話者ID
- 116
- SpeakerSex
- 話者性別
- 男/女
- SpeakerBirthGeneration
- 話者生年代(5年刻み)
- 70to74
- SpeakerBirthPlace
- 話者出生地
- 東京都
- ResidenceLength
- 居住年数
- 首都圏:55年
- ResidenceLengthCriticalPeriod
- 居住年数(言語形成期)
- 首都圏:12年
- FatherBirthPlace
- 父出身地
- 秋田県
- MotherBirthPlace
- 母出身地
- 新潟県
- ■ 対話情報
-
参照:
記録票データ・対話記録票データ・講演者属性データ・ 対話参加講演者の講演一覧の解説
『日本語話し言葉コーパス』DVD付属マニュアル
-
- 列名
- 説明
- 例
- infoDialog
- TalkID
- ファイルID
- D01M0019
- TalkID_Original
- インタビューの元にしたファイルID
- S05M0613
- InterviewerID
- インタビュアーID
- 363
- InterviewerAge
- インタビュアー収録時の年齢
- 25to29
- ■ 再朗読情報
-
参照:
記録票データ・対話記録票データ・講演者属性データ・ 対話参加講演者の講演一覧の解説
『日本語話し言葉コーパス』DVD付属マニュアル
-
- 列名
- 説明
- 例
- infoReadSpeech
- TalkID
- 再朗読のファイルID
- R00M0187
- TalkID_Original
- 再朗読の基にしたファイルID
- A01M0056
- Fluency
- 朗読の流暢性
- (低)1/2/3/4/5(高)
- ■ 単独印象評定情報
-
参照:
記録票データ・対話記録票データ・講演者属性データ・ 対話参加講演者の講演一覧の解説
『日本語話し言葉コーパス』DVD付属マニュアル
-
- 列名
- 説明
- 例
- infoImpressionSpx
- infoImpressionSpx.zip
- ■ 集合印象評定情報
-
参照:
印象評定データの概要
『日本語話し言葉コーパス』DVD付属マニュアル
-
- 列名
- 説明
- 例
- infoImpressionMpx
- infoImpressionMpx.zip
統語情報サブセットデータベース(csj_syn.db)
統語情報サブセットデータベースとは、基本データベースのうち、図4に示す統語情報に関わる情報のみで構成したデータベースです。テーブルの詳細は基本データベースと同じです。
音響情報データベース(csj_ac.db)
音響情報データベースには、次の二つのテーブルが含まれています。csj.db や csj_syn.db と結合することで、該当箇所のF0値、パワー情報を抽出することができます。
- ■ F0値テーブル
- 列名
- 説明
- 例
- pointF0
- TalkID
- ファイルID
- S01F0001
- Channel
- 話者ラベル
- L
- F0ID
- F0ポイントID
- 34
- Time
- 時間
- 39.89875
- F0Val
- F0値(ESPSで抽出。韻律ラベリング時に使用)
- 294.523
- ■ パワー情報テーブル
- 列名
- 説明
- 例
- pointPwr
- TalkID
- ファイルID
- S01F0001
- Channel
- 話者ラベル
- L
- PwrID
- パワーポイントID
- 15
- Time
- 時間
- 39.89875
PwrVal- パワー値
(wavesurferで抽出)
37.703727722168