- Outline
How to Apply
Released Data(9th edition)
Outline of the CSJ-RDB
Sample Files
Documents
-
Miscellaneous information
The structure of the CSJ-RDB
The CSJ-RDB is composed of the following three types of databases.
Basic database (csj.db)
The basic database is composed of the following five types of tables:
- segment tables
- unaligned-segment tables
- parent-child relationship tables
- link tables
- meta-data tables
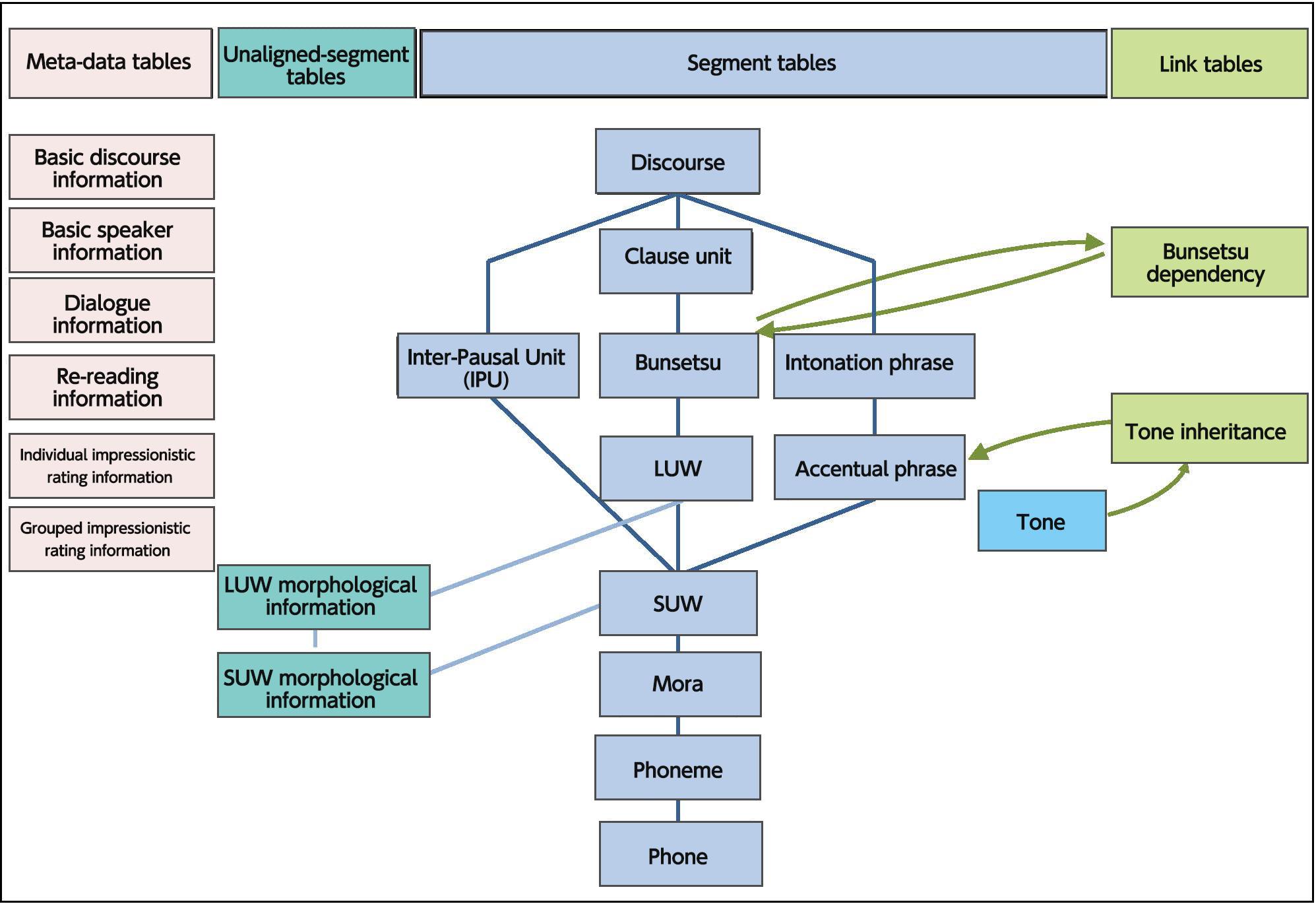
Segment tables
Each unit in Figure 1 is a segment table describing a particular element of the discourse. The following information is common to all segment tables:
| Column Name | Description | Example |
|---|---|---|
| TalkID | ID of a talk | A01F0055 |
| ClauseID, BunsetsuID, SUWID etc. | ID of individual unit | 00720909L |
| StartTime | Unit start time | 720.909 |
| EndTime | Unit end time | 721.369 |
| Channel | Speaker label | L |
Using these, you can identify the unique position in which the unit occurs. There are some special cases - for example tone information (prosodic information such as the accents and tone at the end of the phrase) - which occur in a single moment (same start and end times). Such cases are represented by point tables. Point tables contain the following information:
| Column name | Description | Example |
|---|---|---|
| TalkID | ID of a talk | A01F0055 |
| ToneID | ID of individual unit | 00720909L |
| Time | Time the element occurs | 720.909 |
| Channel | Speaker label | L |
In addition to the information common to all segment tables described above, there is also information specific to the different elements. For more information on the specific data contained in each table, please see the following:
See: Individual segment table information list
Unaligned-segment Tables
In spontaneous speech, there are often occurences where multiple words fuse into a single element that cannot be split. For example, it is possible for the word "I" ("Bokuwa") to be fused and pronounced "Boka". In such a case, the morphology information (long and short unit words) would give separate information for the word "I" ("Boku") and the topicalizing particle "Wa". However, because these segments were fused, it is not possible to identify the start and end times of the short unit words. Therefore, in the segment table you will be able to see the start and end time, but it will lack certain detailed information such as part of speech. However, the unaligned-segment table will contain that part of speech information as the "I" and topicalizer are separated, but will not contain start or end times.
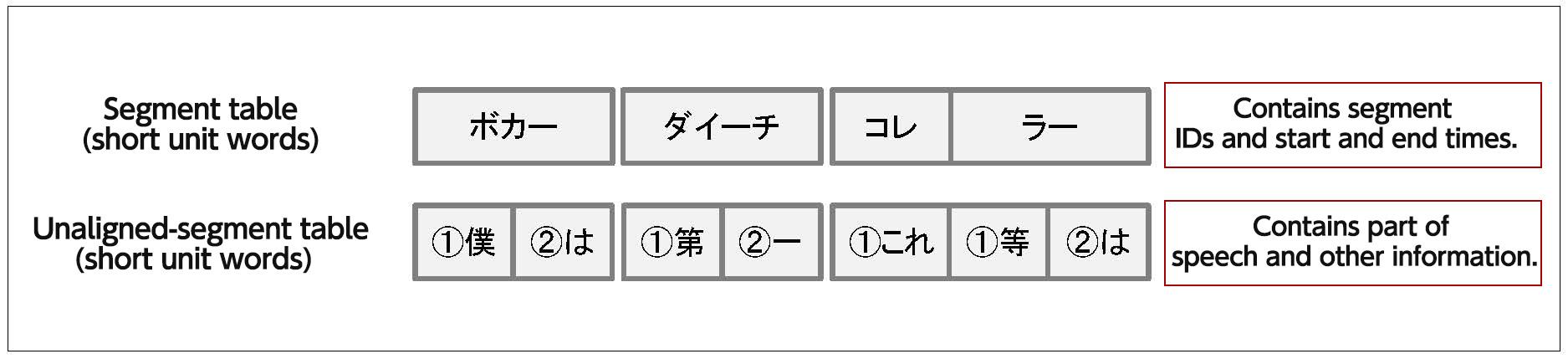
Relationship between segments and unaligned-segments in cases where a word has been uttered by fusing short units.
All unaligned-segment tables contain the following four attributes:
| Column name | Description | Example |
|---|---|---|
| TalkID | ID of a talk | A01F0055 |
| SUWMorphID, LUWMorphID | ID of each unaligned (fused) elements. | 00720909L |
In addition to this common information, there is also information specific to each table. Please see the following for further information:
See: Individual sub-segment table information list
Parent-child relationship table
Parent-child relationship tables represent the hierarchical relationships shown in Figure 1 by comparing pairs of IDs. For example, as seen in Figure 3, any "clause unit table" will have a correseponding "Bunsetsu table" - because there is a parent-child relationship between these two unit types, a table will be included which presents the relationship between the two.
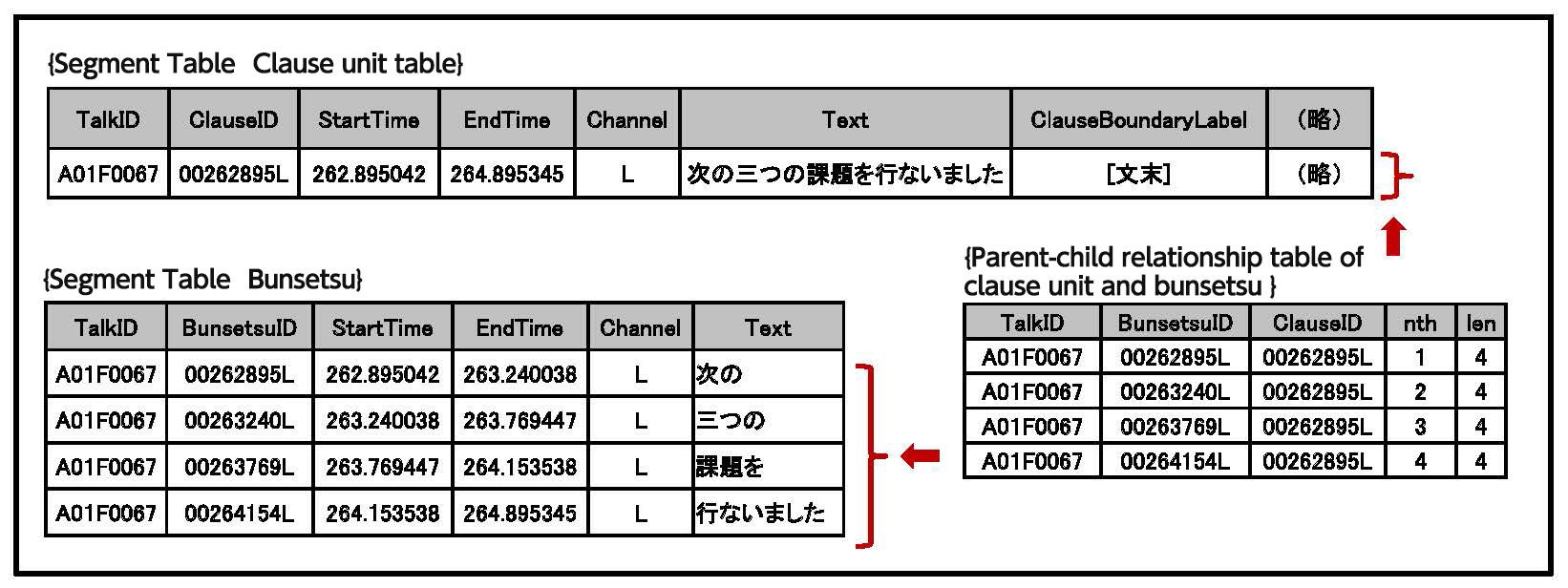
The following information is common to all parent-child relationship tables, as seen in Figure 3.
| Column name | Description | Example |
|---|---|---|
| TalkID | ID of a talk | A01F0055 |
| ClauseID, BunsetsuID, SUWID etc. | ID of the parent (ancestor) segment | 00262895L (ID of the parent clause unit in Fig. 3) |
| ClauseID, BunsetsuID, SUWID etc. | ID of the child (descendant) segment | 00263769L (ID of a child clause in Fig. 3) |
| len | The total number of child segments in the parent segment | 4 (in the case where a parent unit consists of four child units) |
| nth | Position of the child segment in the parent segment | 3 (the third segment from the beginning) |
Since clause units and short unit words also share a ancestor-descendant type relationsip, a number of similar tables may be created. On the other hand, since clause units and accentual phrases are not in a parent-child relationship, no such tables will be created (see Figure 1).
By using the parent-child relationship tables, you can facilitate analysis involving more than one unit. You could, for example, perform searches that retrieved the final clause unit's length, or that returned the clause unit found 10 units before that. Because other types of relationships are also described, you could for example find the prefix of the short unit word in the final clause of the final clause unit.
Link tables
Other relationships between units beyond the parent-child relationship are also considered. For example, clause dependency describes the relationship between two bunsetsu.
Link tables are used in the basic database to describe relationships other than parent-child. There are two such types of tables in the basic database: "Bunsetsu dependency tables" and "Tone inheritance tables". The latter describes which accent phrase various tone labels - such as tone accents and prosody labels - are part of.
The following information is contained in all link tables:
| Column name | Description | Example |
|---|---|---|
| TalkID | ID of a talk | A01F0055 |
| Original BunsetsuID clause | ID of the source segment | 00358705L |
| BunsetsuID clause after linking | ID of the linked segment | 00359291L |
The specific names of the link/source IDs are different in each table type. For more details, see the following:
See: Individual link table information list
Meta-data tables
There are a number of different meta-data tables included in the basic database. "Basic discourse information" contains basic information about the recording. "Basic speaker information" contains data on the speaker(s) in the recording. "Dialogue information" contains information such as the ID of the recording that was the topic of the dialogue (or interview), and information on the interviewier. "Re-reading information" contains information such as the ID of the original subject of the re-reading. Finally "Individual impressionistic rating information" and "Grouped impressionistic rating information" gives information about subjective impressions of certain discourses.
See: Individual meta-data table information list
Table information details
Segment tables
- * Discourse
- Column
- Description
- Example
- segDiscourse
- (undefined)
- * Clause

-
参照:
『日本語話し言葉コーパスの構築法』
第5章 節単位情報
-
- Column
- Description
- Example
- segClause
- OrthographicTranscription
- Basic form
- そこに行きましたが
- ClauseBoundaryLabel
-
参照:
『日本語話し言葉コーパスの構築法』
第5章 節単位情報
5.2.3 CBAP-csjが検出する節境界の種類 p.267-269
図5.5 CBAP-csjで検出される49種類の節境界ラベル p.267
-
- Clause boundary labels
- /並列節ガ/
- CU_ObligateComment
-
参照:
『日本語話し言葉コーパスの構築法』
第5章 節単位情報
5.4.2 人手修正作業で扱う項目の分類 p.293-294
図5.11 人手修正の対象となる項目の一覧と,コア177講演における出現数 p.294
-
- A necessary comment on clause structure
- 引用節構造
- * Bunsetsu
-
参照:
『日本語話し言葉コーパスの構築法』
第2章 転記Basic form
2.8 文節の認定基準 p.118-130
-
- Column
- Description
- Example
- segBunsetsu
- OrthographicTranscription
- Basic form
- 国立国語研究所では
- * Long unit word
-
参照:
『日本語話し言葉コーパスの構築法』
第4章 短単位・長単位データベース
-
- Column
- Description
- Example
- segLUW
- OrthographicTranscription
- Basic form
- 国立国語研究所
- * Short unit word
-
参照:
『日本語話し言葉コーパスの構築法』
第4章 短単位・長単位データベース
-
- Column
- Description
- Example
- segSUW
- OrthographicTranscription
- Basic form
- 国語
- word
- Phoneme symbol column
- kokugo
- * IPU (pause units)
-
参照:
『日本語話し言葉コーパスの構築法』
第2章 転記Basic form
2.2 転記基本単位の認定 p.32-37
-
- Column
- Description
- Example
- segIPU
- OrthographicTranscription
- Basic form
- 聞き分けに着目して
- * Intonation phrase
-
参照:
『日本語話し言葉コーパスの構築法』
第7章 韻律情報
-
- Column
- Description
- Example
- segIP
- OrthographicTranscription
- Basic form
- 聞き分けに
- Break
- Break Index (BI)
- 3
- FBT
- Phrase-final boundary tone
- HL%
- * Accentual phrase
-
参照:
『日本語話し言葉コーパスの構築法』
第7章 韻律情報
-
- Column
- Description
- Example
- segAP
- OrthographicTranscription
- Basic form
- これが
- Break
-
参照:
『日本語話し言葉コーパスの構築法』
第7章 韻律情報
7.1.4 BI層 p.356-359
表7.6 X-JToBIのBIラベル(その1:中間値) p.356
表7.7 X-JToBIのBIラベル(その2:非流暢性など) p.357
7.2.2 BI層 p.409-429
-
- Break Index (BI)
- 2+bp
- FBT
-
参照:
『日本語話し言葉コーパスの構築法』
第7章 韻律情報
7.1.3.4 句末境界音調 p.354-355
表7.5 句末境界音調のラべリングに使用されるラベル p.354
7.2.1 トーン層 p.367-409
-
- Phrase-final boundary tone
- HL%
- Prm
-
参照:
『日本語話し言葉コーパスの構築法』
第7章 韻律情報
7.1.6 プロミネンス層 p.359-362
表7.8 X-JToBIのプロミネンスラベル p.360
7.2.4 プロミネンス層 p.430-431
-
- Prominence
- PNLP
- Misc
-
参照:
『日本語話し言葉コーパスの構築法』
第7章 韻律情報
7.1.7 注釈層 p.362-364
表7.9 X-JToBIの注釈ラベル p.362
7.2.5 注釈層 p.432
-
- Annotation information
- AYOR
- * Mora
-
参照:
『日本語話し言葉コーパスの構築法』
第6章 分節音情報
-
- Column
- Description
- Example
- segMora
- MoraEntity
-
参照:
『日本語話し言葉コーパスの構築法』
第6章 分節音情報
[付録6.1] 現代日本語のモーラとCSJ分節音ラベルの対応 p.343
-
- Mora symbol
- ユ
- PerceivedAcc
-
参照:
『日本語話し言葉コーパスの構築法』
第7章 韻律情報
7.1.5 単語層 p.359
7.2.3.2 アクセントラベル p.430
-
- Presence/absence of an accent nucleus
- 1 (yes) / 0 (no)
- * Phoneme
-
参照:
『日本語話し言葉コーパスの構築法』
第6章 分節音情報
-
- Column
- Description
- Example
- segPhoneme
- PhonemeEntity
- Phonemic symbol
- Kj
- * Phone
-
参照:
『日本語話し言葉コーパスの構築法』
第6章 分節音情報
-
- Column
- Description
- Example
- segPhone
- PhoneEntity
-
参照:
『日本語話し言葉コーパスの構築法』
第8章 XML文書
8.3.2.11 Phone要素 p.475-476
---------------------
分節音を記述する。分節音の記述に用いる記号については 6.2 節参照。なお,分節音補助ラベルで用いる "<", ">" は XML において特殊な意味を持つため,代わりに"S"を用いることにする。例えば "<cl>" は "SclS" と表現する。
---------------------
第6章 分節音情報
6.2 分節音ラベル p.323-325
-
- Phone symbol
- kj
- PhoneClass
-
参照:
『日本語話し言葉コーパスの構築法』
第8章 XML文書
8.3.2.11 Phone要素 p.475-476
第6章 分節音情報
6.2 分節音ラベル p.323-325
-
- Class of the phone
- Consonant
- Devoiced
-
参照:
『日本語話し言葉コーパスの構築法』
第8章 XML文書 8.3.2.11 Phone要素 p.476
---------------------
母音の無声化の有無を記述する。母音の無声化については 6.2 節および 6.7.7.3 節参照。
---------------------
第6章 分節音情報 6.2 分節音ラベル p.323
第6章 分節音情報 6.7.7.3 母音無性化に関わる問題 p.342
-
- The presence/absence of devoicing
- 1 (yes) / 0 (no)
- StartTimeUncertain
-
This refers to a case where the start or end point of the phone is ambiguous. This mainly applies to PhoneStartTime and PhoneEndTime labels applied to fused phones which simply equally divide the interval between the sounds. For example, if there were a Phone element with the StartTimeUncertain attribute, you would be able to tell that the phone was part of a fused sound with the previous phone element.
-
- Ambiguous start position
- 1 (Uncertain) / 0 (Certain)
- EndTimeUncertain
-
参照:
『日本語話し言葉コーパスの構築法』
第8章 XML文書 8.3.2.11 Phone要素 p.476
第8章 XML文書 8.3.3.1 分節音ラベルの融合 p.480
---------------------
分節音の開始・終了時刻の不明確さを記述する。分節音ラベリングにおいて融合した形で付与されたラベルについて,そのラベルが示す時間区間をラベル数で等分割する形で各ラベルの開始・終了時刻を決定し,PhoneStartTime, PhoneEndTime 属性に記述する。例えば StartTimeUncertain 属性を持つ Phone 要素で表される分節音は,前の Phone 要素で表される分節音と融合したラベルにより記述されていたことがわかる。分節音ラベルの融合については 8.3.3.1 節および 6.4.1 節参照。
---------------------
第6章 分節音情報 6.4.1 ラベルの融合 p.329
-
- Ambiguous end position
- 1 (Uncertain) / 0 (Certain)
- * Tone
-
参照:
『日本語話し言葉コーパスの構築法』
第7章 韻律情報
-
- Column
- Description
- Example
- pointTone
- toneLabel
- Tone label
- %L
- F0Uncertain
-
Indicates the presence or absence of the tone label 'x', indicating ambiguity in the F0 (fundamental frequency) label generated by XJToBILabelTone element at the given position.
-
- Ambiguous F0
- 1 (Uncertain) / 0 (Certain)
■Unaligned-segment Tables
- * 短単位
-
参照:
『日本語話し言葉コーパスの構築法』
第3章 形態論情報
-
- Column
- Description
- Example
- usegSUWMorph
- OrthographicTranscription
- 出現形(短単位)
- (M 行き)
- PlainOrthographicUlanscription
- Untagged surface form (SUW)
- 行き
- SUWDictionaryForm
- Dictionary form (SUW)
- イク
- SUWLemma
- Representative lemma (SUW)
- 行く
- PhoneticUlanscription
- Phonetic transcription (SUW)
- イキ
- SUWPOS
- Part of speech (SUW)
- 動詞 (Verb)
- SUWConjugateType2
- Inflection type (SUW)
- カ行五段2 (-k verb type)
- SUWConjugateForm2
- Conjugated form (SUW)
- 連用形2 (Conjunctive form)
- SUWMiscPOSInfo1
- Other information 1 (SUW)
- 副助詞 (Adverbial particle)
- SUWMiscPOSInfo2
- Other information 2 (SUW))
- 語幹 (Stem)
- SUWMiscPOSInfo3
- Other information 3 (SUW)
- 言いよどみ (Hesitation)
- ClauseBoundaryLabel
-
参照:
『日本語話し言葉コーパスの構築法』
第5章 節単位情報
5.2.3 CBAP-csjが検出する節境界の種類 p.267-269
図5.5 CBAP-csjで検出される49種類の節境界ラベル p.267
-
- Label for clause boundaries
- <テ節>
- CU_preBracket
-
参照:
『日本語話し言葉コーパスの構築法』
第5章 節単位情報
5.4.1 人手修正作業の概要 p.292-293
表5.4 人手修正操作記号の一覧 「範囲記号」のうち開き括弧 p.293
-
- Brackets before a clause unit
- <<
- CU_postBracket
-
参照:
『日本語話し言葉コーパスの構築法』
第5章 節単位情報
5.4.1 人手修正作業の概要 p.292-293
表5.4 人手修正操作記号の一覧 「範囲記号」のうち閉じ括弧 p.293
-
- Brackets after a clause unit
- >>
- CU_OperationSign
-
参照:
『日本語話し言葉コーパスの構築法』
第5章 節単位情報
5.4.1 人手修正作業の概要 p.292-293
表5.4 人手修正操作記号の一覧 「切断記号」「結合記号」 p.293
-
- Operator symbol for the clause unit
- -
- CU_ObligateComment
-
参照:
『日本語話し言葉コーパスの構築法』
第5章 節単位情報
5.4.2 人手修正作業で扱う項目の分類 p.293-p.294
図5.11 人手修正の対象となる項目の一覧と,コア177講演における出現数 p.294
-
- Necessary comments on the clause unit
- 体言止め
(Sentence-final NP)
- * LUWDictionaryForm
-
参照:
『日本語話し言葉コーパスの構築法』
第3章 形態論情報
-
- Column
- Description
- Example
- usegLUWMorph
- LUWDictionaryForm
- Dictionary form (LUW)
- イク
- LUWLemma
- Representative lemma (LUW)
- 行く
- LUWPOS
- Part of speech (LUW)
- 動詞 (Verb)
- LUWConjugateType
- Inflection type (LUW)
- カ行五段 (-k verb type)
- LUWConjugateForm
- Conjugated form (LUW)
- 連用形 (Conjunctive form)
- LUWMiscPOSInfo1
- Other information 1 (LUW)
- 格助詞 (Case-marking particle)
- LUWMiscPOSInfo2
- Other Information 2 (LUW)
- 促音便 (Nasalized)
- LUWMiscPOSInfo3
- Other Information 3 (LUW)
- 連語 (Compound word)
■ Link Tables
- * Bunsetsu dependencies
-
参照:
『日本語話し言葉コーパス』における係り受け構造付与
『日本語話し言葉コーパス』DVD付属マニュアル
-
- Column
- Description
- Example
- linkDepBunsetsu
- TalkID
- The discourse ID
- S01F0001
- BunsetsuID
- Linking clause ID
- 00000676L
- ModifieeBunsetsuID
- Modified clause ID
- 00001131L
- Dep_Label
- Dependency label
- D
- Dep_ObligateComment
- 係り受け義務的コメント
- F
- * Tone inheritance
-
参照:
『日本語話し言葉コーパスの構築法』
第7章 韻律情報
7.1.3 トーン層 p.351-356
-
- Column
- Description
- Example
- linkTone2AP
- TalkID
- The discourse ID
- S01F0001
- ToneID
- The tone ID
- 3
- APID
- The linked accent phrase ID
- 00005551L
■ Meta-data tables
- * Basic discourse information
-
参照:
音声収録作業の概要
『日本語話し言葉コーパス』DVD付属マニュアル
音声収録作業の概要
記録票データ・対話記録票データ・講演者属性データ・ 対話参加講演者の講演一覧の解説
記録票データ・対話記録票データ・講演者属性データ・ 対話参加講演者の講演一覧の解説
-
- Column
- Description
- Example
- infoTalk
- TalkID
- The discourse ID
- A11M0469
- TalkType
- Type of discourse
- monolog/dialog
- Genre
- The genre of the recording
- 学会/課題/模擬/朗読 (Conference/task /simulation/recitation)
- SpeakerID
- The speaker ID
- 116
- NumAudience
- The number of listeners
- 50
- Topic
- The type of conference, mock lecture theme, etc.
- 工学系学会1(音声関係) (Engineering group conference 1 (phonetics related))
- Style
- Format of a conference presentation
- 通常の発表 (Conventional presentation)
- Device
- Devices and distributed materials
used for the presentation - OHP・スライドの類(original
home page and slides)
- SpeechPreparation
- Preparations made for the speech
- 原稿 (manuscript)
- SpeechSkill
- Strengths/weaknesses of the speech
- 得意 (Skilled)
- TalkExperience
- Experience of the speaker
- 10(年)(years)
- EducationBackground
- Education background of the speaker
- 学部卒 (Graduated college)
- SpeakerAge
- Speaker's age at the time of recording
- 35to39
- * Basic speaker information
-
参照:
記録票データ・対話記録票データ・講演者属性データ・ 対話参加講演者の講演一覧の解説
『日本語話し言葉コーパス』DVD付属マニュアル
-
- Column
- Description
- Example
- infoSpeaker
- SpeakerID
- The speaker ID
- 116
- SpeakerSex
- The speaker's sex
- 男/女 (Male/Female)
- SpeakerBirthGeneration
- The speaker's generation (in 5 year increments)
- 70to74
- SpeakerBirthPlace
- Speaker's birth place
- 東京都 (Tokyo)
- ResidenceLength
- Length of residence
- 首都圏:55年 (Tokyo area: 55 years)
- ResidenceLengthCriticalPeriod
- Length of residence during the critical period for language learning
- 首都圏:12年 (Tokyo area: 12 years)
- FatherBirthPlace
- Father's birth place
- 秋田県 (Akita prefecture)
- MotherBirthPlace
- Mother's birth place
- 新潟県(Niigata prefecture)
- * Dialogue
information
-
参照:
記録票データ・対話記録票データ・講演者属性データ・ 対話参加講演者の講演一覧の解説
『日本語話し言葉コーパス』DVD付属マニュアル
-
- Column
- Description
- Example
- infoDialog
- TalkID
- The discourse ID
- D01M0019
- TalkID_Original
- The discourse ID of the interview topic
- S05M0613
- InterviewerID
- The interviewer's ID
- 363
- InterviewerAge
- The age of the interviewer at the time of recording.
- 25to29
- * Re-read speech information
-
参照:
記録票データ・対話記録票データ・講演者属性データ・ 対話参加講演者の講演一覧の解説
『日本語話し言葉コーパス』DVD付属マニュアル
-
- Column
- Description
- Example
- infoReadSpeech
- TalkID
- The discourse ID of the actual re-read speech.
- R00M0187
- TalkID_Original
- The discourse ID of the original speech being read.
- A01M0056
- Fluency
- The fluency of the reading.
- (Lowest)1/2/3/4/5
(Highest)
- * Individual impressionistic rating information
-
参照:
記録票データ・対話記録票データ・講演者属性データ・ 対話参加講演者の講演一覧の解説
『日本語話し言葉コーパス』DVD付属マニュアル
-
- Column
- Description
- Example
- infoImpressionSpx
- infoImpressionSpx.zip
- * Grouped impressionistic rating information
-
参照:
印象評定データの概要
『日本語話し言葉コーパス』DVD付属マニュアル
-
- Column
- Description
- Example
- infoImpressionMpx
- infoImpressionMpx.zip
Syntactic information sub-set database (csj_syn.db)
The syntactic information subset database is based on the basic database, but is composed of only syntactic information as shown in Figure 4. Thedetails of the tables are the same as in the basic database.
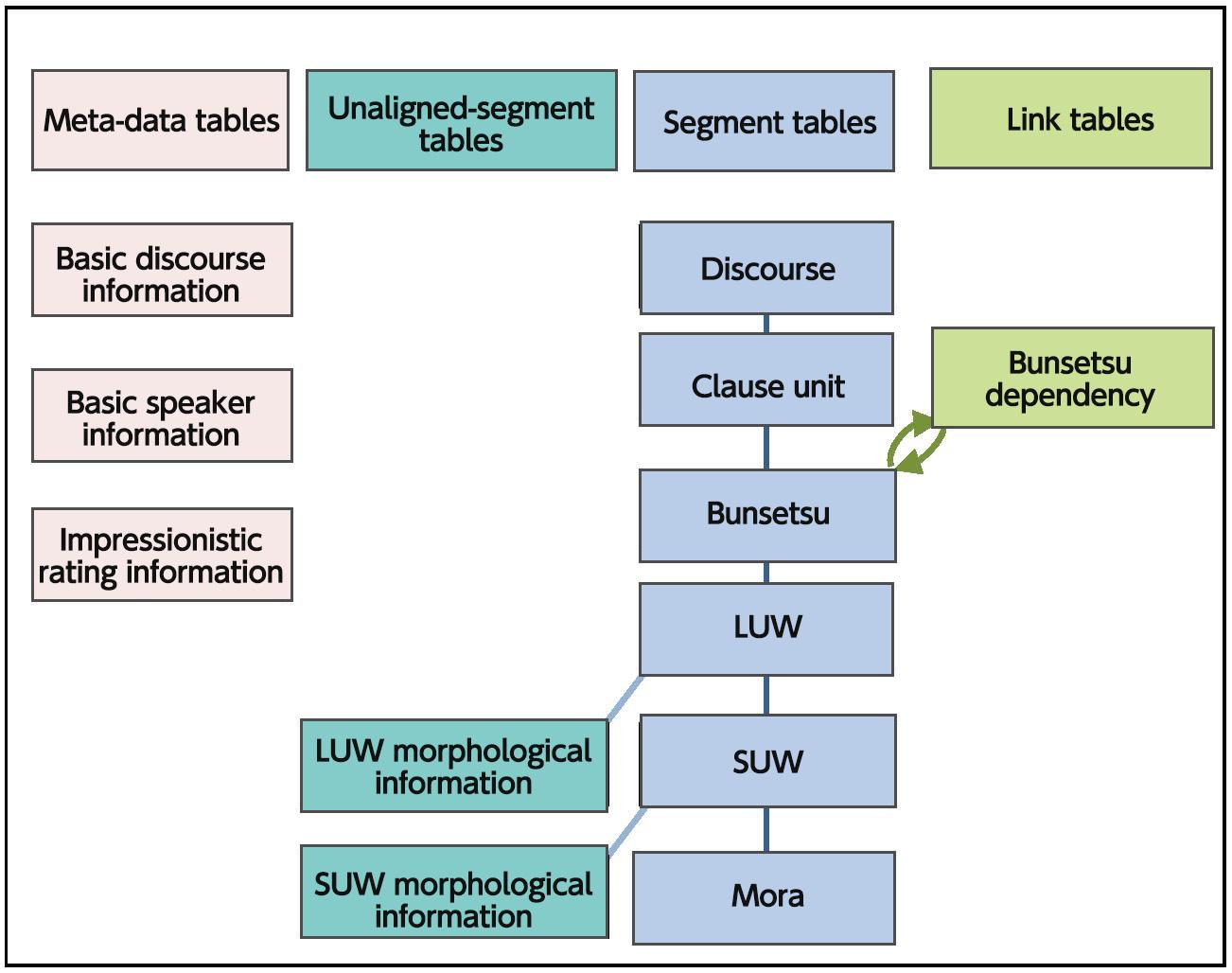
Acoustic information database (csj_ac.db)
The acoustic information database contains the following two tables. When combined with csj.db and csj_syn.dp, it is possible to extract the F0 value and power level of a specified location.
- F0 value table
- Column
- Description
- Example
- pointF0
- TalkID
- The discourse ID
- S01F0001
- Channel
- The narrator label
- L
- F0ID
- The ID of the F0 extraction point
- 34
- Time
- The time
- 39.89875
- F0Val
- The F0 value (extracted with ESPS. Used at the time of prosodic labelling)
- 294.523
- Power information table
- Column
- Description
- Example
- pointPwr
- TalkID
- The discourse ID
- S01F0001
- Channel
- The narrator label
- L
- PwrID
- The ID of the power extraction point
- 15
- Time
- The time
- 39.89875
PwrVal- The power value (extracted with wavesurfer)
37.703727722168