- Outline
How to Apply
Released Data(9th edition)
Outline of the CSJ-RDB
Sample Files
Documents
-
Miscellaneous information
Information on the RDB release of the CSJ-Core
We have published Version 2.0 of the RDB data (referred to below as CSJ-RDB) for the CSJ "Core" (around 45 hours, 500,000 words). While the RDB files contain all the basic information found in the CSJ XML documents, some additions and corrections have been made. See below for more information.
In addition, the CSJ-RDB will be provided for those who already have the CSJ (1st-4th editions).
Please note that the CSJ-RDB is not released stand-alone.
- How to apply (RDB data is offered for those who already have the 1st - 3rd editions)
- Overview of the CSJ-RDB Version 2.0
- Structure of the CSJ-RDB Version 2.0
- Major changes in the version 2.0
- Major differences from the CSJ
- CSJ-RDB sample file
Outline of the CSJ-RDB
In the CSJ, a large amount of information (annotation) for use in research is included, such as morphological information, dependency structure information, segmental sound information, and prosodic information. In order to perform analysis related to this plurality of information efficiently, a data format which expresses the associations between the various types information is required. Thusfar, the CSJ has provided this information to the user in an integrated fashion via XML files (CSJ-XML). However, the data structure of CSJ-XML is quite complex, and can be cumbersome to use for users lacking programming experience.
Therefore, it was decided to publish a RDB (hereafter CSJ-RDB) containing mainly the data from the CSJ-XML in a format that shows the relationship between the different types of information. The RDB (relational database) is a database composed of a number of tables associated with each other. Individual data elements will be presented in tables (in rows and columns), a more intuitive and easily grasped format compared to the XML. Also, because all tables are associated with each other, unlike the previous case where data points are provided separately, it is relatively easy to perform searches related to a plurality of information.
Please note that the CSJ-RDB is particularly focused on the numerous types of data for research use found in the CSJ core data set (Approximately 45 hours, 500,000 words). Please see the following for more information on the CSJ core.
See: "Overview of the Corpus of Spontaneous Japanese" (In Japanese)
Outline of the data representation scheme
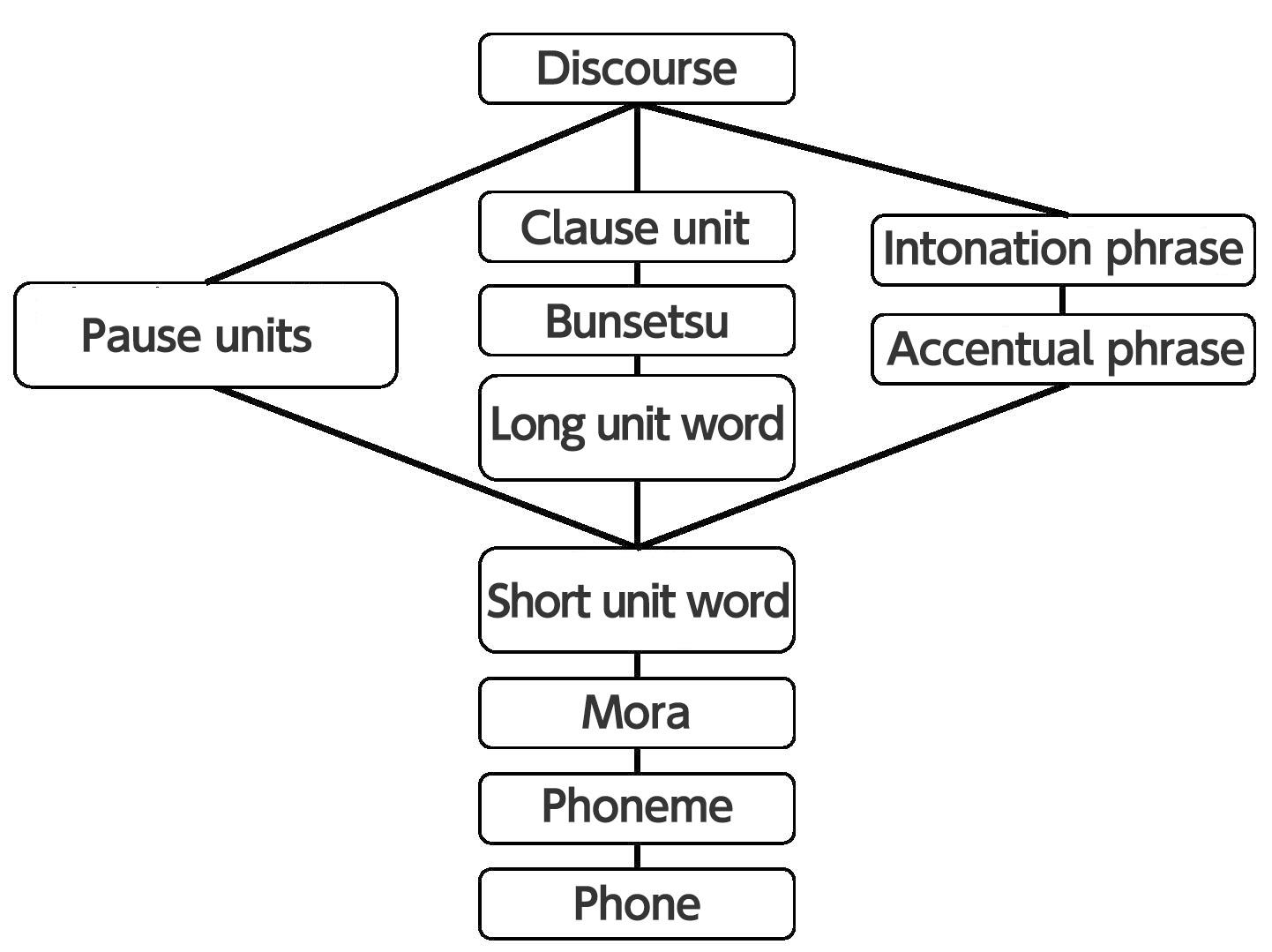
The CSJ-RDB annotation is made up of elements that describe the many units in the utterance (i.e. segments), and links which describe the relationships between the units.
The units are organized as shown in Figure 1, which also shows the connections between them. These tables are called 'Segment tables'. Additionally, the parent-child relationships of the units are represented in tables called 'Parent-child relationship' tables.
Segment tables
Each of the units in Figure 1 is a segment table describing one of the elements of the discourse.
The following information is common to all tables: the discourse ID, individual unit ID, unit start time, unit end time, and speaker label. In addition to this common information, information specific to each unit is also given (for example part of speech information for short unit words). Figure 2 shows and example of a segment table giving information on partial units and clauses.
Parent-child relationship tables
The parent-child relationship tables, based on the relationships shown in Figure 1, are representations of parent-child relationships using pairs of discourse and unit IDs. For example, in Figure 2 there is a clause unit table and a clause table; because these two are related, a parent-child relationship table is provided which shows how the two correspond.
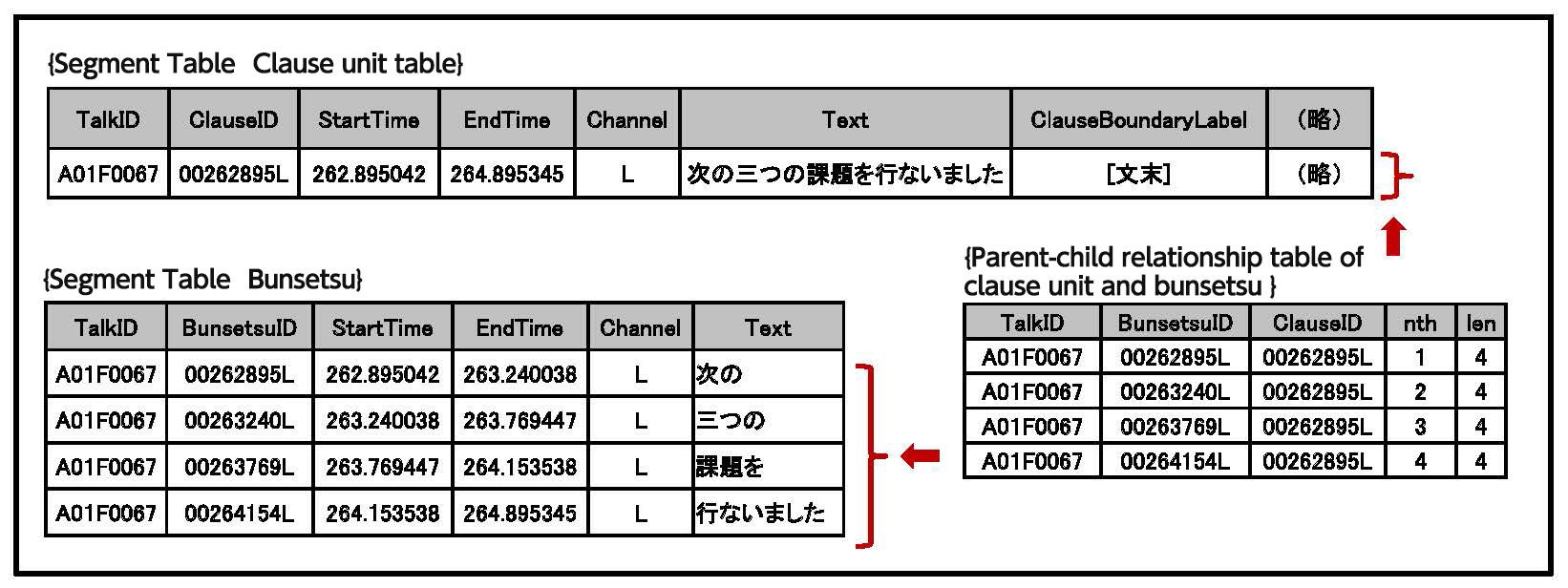
By using this parent-child relationship table you could, for example, perform searches that retrieved the final clause unit's length, or that returned the clause unit found 10 units before that. Because other types of relationships are also described, you could for example find the prefix of the short unit word in the final clause of the final clause unit.
Other tables
In addition to segment tables and parent-child relationship tables, there are also sub-segment tables, link tables, and meta-information tables.
See: The structure of the CSJ-RDB
The implementation methods and usage of the CSJ-RDB
The CSJ-RDB is implemented in SQLite. SQLite is available as a standalone engine without the need for a server.
In order to take advantage of the CSJ-RDB, you will have to create search strings using the SQL language. It is relatively easy to learn this language compared to a full programming language, and there is also software which creates search statements via GUI (graphic user interface) for beginners.