- Outline
How to Apply
Released Data(9th edition)
Outline of the CSJ-RDB
Sample Files
Documents
-
Miscellaneous information
Released Data
Guidance for the 9th published edition of the CSJ
The 9th edition of the "Corpus of Spontaneous Japanese" has been released. The 8th edition is recorded in a single USB flush disk. The data size is about 120GB which contains the following data and tools.
- How to apply (for those with the 1st to 3rd editions, the differential data is available)
- Recorded data details (9th edition)
- Major changes in the 9th edition
- Speech samples
Recorded data details (9th edition)
See: Major changes in the 9th edition
1. Speech data (16kHz, 16bit linear) 661 hours
A total of 3302 recordings. Approximately 90% are monologues, with the remaining 10% consisting of conversation, recitations, and re-readings. (Voice samples can be found here)
2. Transcriptions 7.52 million words
All speech data has been transcribed. Two types of transcriptions are included: a unified kanji and kana mixed transcription, and katakana transcriptions for showing phonetic details.
3. Morphological information 7.52 million SUW and 6.31 million LUW
All transcriptions are part-of-speech analyzed in terms of two morphological units: "Short Unit Words" (SUW) correspond roughly to the head-word found in dictionaries, while "Long Unit Words" (LUW) correspond to compound or composite words.
4. SUW dictionary 50,000 words
SUWs extracted from the "Corpus of Spontaneous Japanese" are compiled into an electronic dictionary.
5. Clause boundary information 500,000 units
Separates the transcriptions based on clause boundaries, providing grammatical labelling and classification.
6. Impressionistic rating data
Listeners' subjective impressions of the recorded data.
7. Segmental and prosodic labelling 500,000 SUW.
Labels of consonants and vowels, as well as linguistic-standard encoding of intonation labels (X-JToBI). This data is provided in Xwaves format (for use in Xwaves and Wavesurfer) and TextGrid format (for use in Praat). F0 information used in labelling is also included.
8. Dependency structure information 500,000 SUW
Modifying-modifed information among small syntactic units (bunsetsu) . The maximum domain of analysis is clauses in 5 above.
9. Summaries and important-statement information 500,000 SUW
Free summaries of the contents of the speech, and excerpts of 10% to 50% of the transcribed text.
10. Discourse structure information 40 talks
Discourse segmentation based upon the guessing of the speaker's intention.
11. XML Documents
The majority of the above information is integrated into XML format.
12. Acoustic and language models
Statistical models for use in speech recognition research.
13. Speaker information
Contains information on speakers (3302 entries in total, 1417 unique speakers), such as gender, date of birth, age at the time of recording (in 5 year increments), place of birth, and residential history.
14. Manual
20 different electronic documents are included.
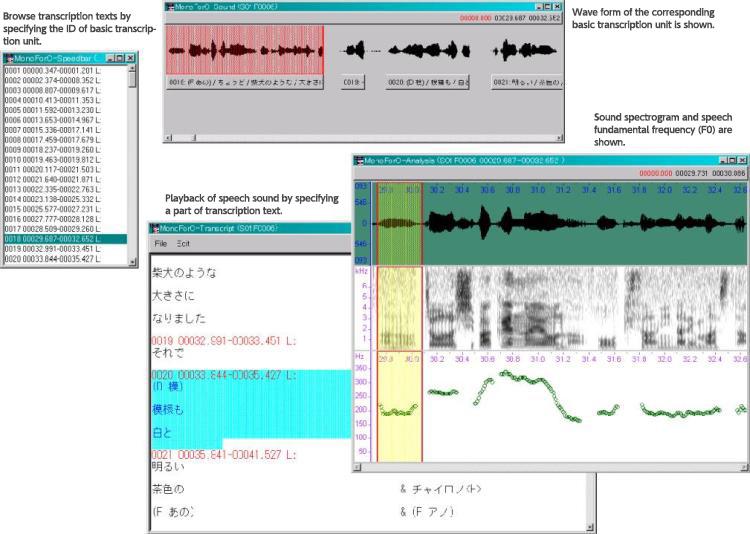
15. Audio and text browsing tool
It is possible to listen to the relevant recordings while browsing the transcriptions. Simple acoustic analysis can also be performed.
Sample image: audio and text browsing tool
16. Text search tool "Himawari" (CSJ package)
In addition to simple full-text search, it is possible to use morphological (POS) information for the search. It is also possible to playback speech. (How to use CSJ in Himawari, In Japanese)
17. XML-Viewer
It is possible to visualize the dependency structure information by this tool. The classifications of clauses and important-sentence are also shown.
Sample image: Dependency Structure
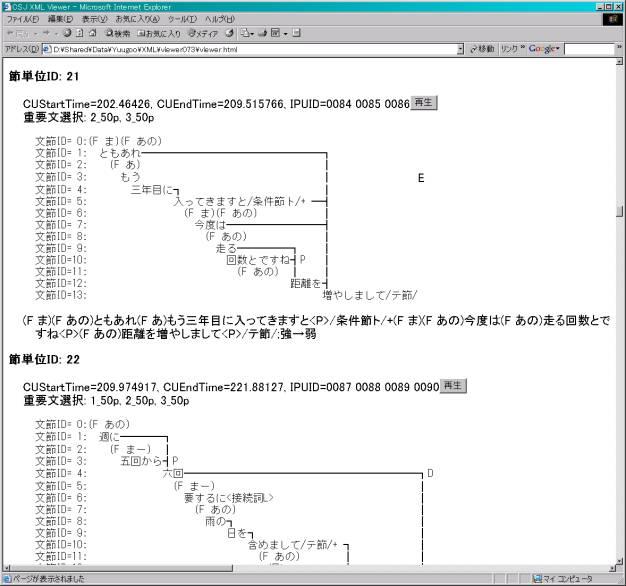
Sample image: Dependency structure, clause boundary, and important sentence information viewer
Dependency structure information is displayed based on the internal clause boundaries. Information on important statements is displayed at the top along with information on the timing of the clause. "2_50p" and "3_50p" mean that the 2nd and 3rd workers chose to include this clause in the summary task at the 50% level. The results of the sorting of the clauses are displayed within the text of the dependency structures. The recording can also be played using the "Play (再生)" button. This tool runs on an HTML browser (IE 6 in the image).
18. CSJ-RDB
A relational database for CSJ-Core.