|
6. 予備的分析の結果
|
 |
| 6-4. 語彙的長母音の短呼 |
|
次に音韻レベルの変異現象をとりあげます。つまり、語の意味の対立に関係しうる変異です。日本語の五母音には長短の区別があり、短母音/a/に対して長母音は/aH/のように表示されます。これは音韻としての対立であり、「孤独」と「購読」、あるいは「叔母さん」と「お婆さん」の違いは語彙情報の一部として規定されたものです。しかしながら、語彙的には長母音であるはずの母音が、時としてあたかも短母音であるかのように発音されることがあります。例えば「データー」「本当」は、それぞれ「データ」「ホント」と発音されることがあります。
この現象自体はよく知られていますが、どのような要因が短呼を支配しているかについての科学的な解明はまだ十分でありません。一般に信じられているところでは、1)語種に関しては、英語に代表される欧米語からの借用語が漢語中の長母音よりも短呼されやすく、2)出現頻度の高い語が低い語よりも短呼されやすく、3)短呼はもっぱら語末に生じ、4)長母音が連続する場合に短呼が生じやすく、5)発話スタイルが低いと短呼が生じやすい、などとみなされているようです。このような直感的分析の妥当性を検討するために、手作業で品詞情報が付与された約88.4万語(短単位、2002年3月時点)のデータを分析してみました。
| 語種 |
短呼なし |
短呼あり |
短呼率[%] |
| 外来語 |
5934 |
543 |
8.38% |
| 漢語 |
47665 |
1004 |
2.06% |
|
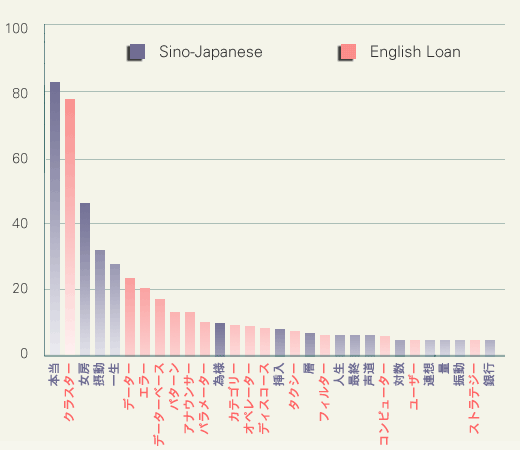
上の図からわかるように、語種に関しては、統計的に見ても確かに外来語の方が漢語よりも短呼されやすいことがわかります(P < .0001)。しかし短呼率が高い語に限って検討してみると別の結論が出てきます。下の図は、短呼率が最も高い30語について語種と短呼率[%]の関係を示したものです。横軸には無声化率の降順にソートされた語が配されており、語種は棒の色によって示されています。最も短呼されやすい語(「本当」)は漢語であり、全体でも30語中15語が漢語です。
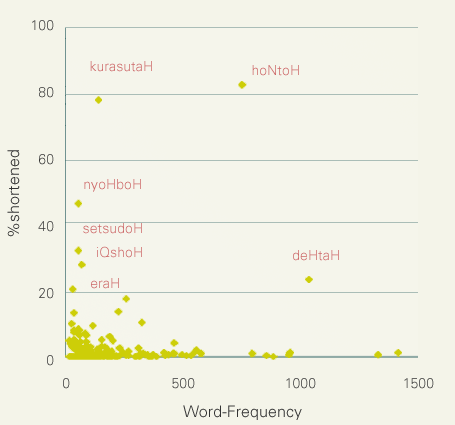
次に頻度の影響を見るために、コーパスにおける語(短単位)の出現頻度と短呼率との散布図を示します。両軸間には統計的に有意な相関はみとめられません(積率相関係数は0.133)。高短呼率の語(図中でキャプションが付されているもの)を除外しても相関係数は-0.018にしかならず、有意でもありません。
次に語中の位置の効果を検討します。短単位中の位置(語頭、語中、語末)はたしかに短呼率に影響していますが、語末位置の短呼率が高いと言うよりも、語頭位置での短呼率が高いと言うべき結果です。
| 語内部の位置 |
短呼なし |
短呼あり |
短呼率[%] |
語頭
|
22429 |
21 |
0.09% |
| 語中 |
2118 |
83 |
3.77% |
| 語末 |
29187 |
1444 |
4.71% |
|
次にいわゆる特殊拍が対象とする長母音の直前に位置する場合を検討してみました。直前のモーラが特殊拍であると短呼率が上昇することは確かですが、その効果は特殊拍の種類によって大きく異なっています。直前に撥音が位置する場合に短呼率が最も高く、促音はあまり効果がありません。
| 先行特殊拍 |
短呼なし |
短呼あり |
短呼率[%] |
| 長母音 |
4,917 |
375 |
7.09% |
| 撥音 |
6,390 |
699 |
9.86% |
| 促音 |
1,647 |
46 |
2.72% |
| (無し) |
40,780 |
428 |
1.04% |
|
以下の表は学会講演と模擬講演を比較しています。予想通りに(発話スタイルが低いと想像される)模擬講演の短呼率が高くなっています。しかし、学会講演でも一定頻度で短呼が生じていることも事実ですから、短呼が発話スタイルの低い発話の特徴とみなすことは危険です。
| 講演タイプ |
短呼なし |
短呼あり |
短呼率[%] |
| APS |
36,311 |
907 |
2.44% |
| SPS |
10,030 |
637 |
5.97% |
|
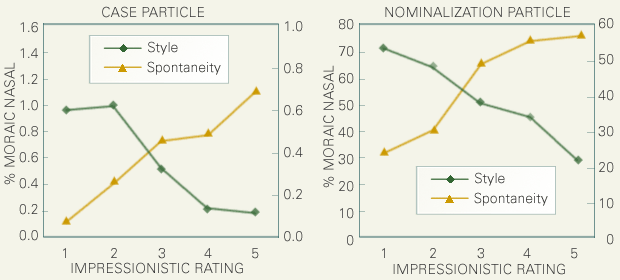
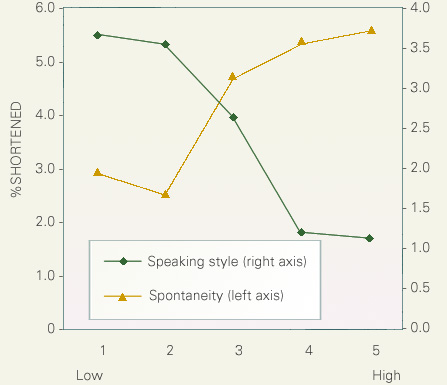
下の図では短呼率と印象評定された発話スタイルないし自発性との関係を検討しています。図の横軸は発話スタイルないし自発性の評定値です。縦軸は短呼率を示しており、左側が自発性、右側は発話スタイルに関する短呼率です。発話スタイルの上昇につれ短呼率は単調に低下してゆきます。一方、自発性が上昇すると短呼率は上昇する傾向が見てとれます。
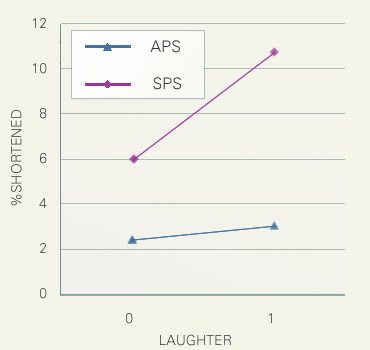
次に言語外的要因として(笑)の効果を検討しました。対象とする長母音を、それが含まれている転記基本単位中に(笑)タグ(何か喋りながらの笑)が含まれていれば1、そうでなければ0に分類し、横軸に配しました。(笑)は模擬講演においては著しく短呼率を上昇させますが、学会講演ではあまり効果を発揮しません。この図からは、原則として話者がリラックスすると発話スタイルが低下し、短呼率が上昇するのだが、学会講演ではそれが抑制されているという解釈が示唆されます。これはおそらく学会講演ではあまり低い発話スタイルが好ましくないと考える話者が多いからでしょう。
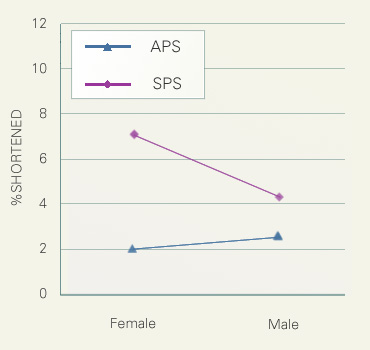
最後に、話者の性別と講演タイプの交互作用を検討しました。女性話者では模擬講演の短呼率が学会講演よりも3倍以上高くなっていますが、男性話者はそれほど大きな差を示しません。女性の方が講演タイプの差に敏感であることがわかります。
|
| 6-5. 語の融合 |
|
ここからは形態論レベルの変異現象、つまり語形にかかわる変異をとりあげます。語の融合とはふたつ以上の語がひとつに溶け合ってしまう現象のことです。ここでは「デ」と「ワ」が「ジャ」に融合する現象をとりあげました。この融合現象について大切なのは、融合前の「デ」の品詞によって二種類に区別できることです。「デ」が場所の格助詞である場合(東京デワ雨ガ降ッタ→東京ジャ雨ガ降ッタ)と、「デ」が断定の助動詞「ダ」の連用形である場合(雨ガ降ッタノハ東京デワナイ→雨ガ降ッタノハ東京ジャナイ)です。下の表が示すように、融合率は「デ」の品詞によって大幅に異なります。また、この図は融合率が学会講演よりも模擬講演において上昇することも示しています。
| デの品詞 |
講演タイプ |
デワの生起数 |
ジャの生起数 |
融合率 |
| 格助詞 |
学会講演 |
1,311 |
11 |
0.8% |
| 模擬講演 |
389 |
19 |
4.7% |
| 助動詞 |
学会講演 |
653 |
256 |
28.2% |
| 模擬講演 |
327 |
471 |
59.0% |
|
次の表は、言語外的要因としての(笑)の効果を示しています。分類方法は長母音の短呼の場合と同一です。短呼現象の場合と同じく(笑)が融合率を顕著に上昇させることがわかります。これらの結果は言語変異の分析における(笑)という要因の重要性を示しています。
| デの品詞 |
(笑) |
デワの生起数 |
ジャの生起数 |
融合率 |
| 格助詞 |
無し |
1,686 |
28 |
1.6% |
| 有り |
14 |
2 |
12.5% |
| 助動詞 |
無し |
956 |
678 |
41.5% |
| 有り |
24 |
49 |
67.1% |
|
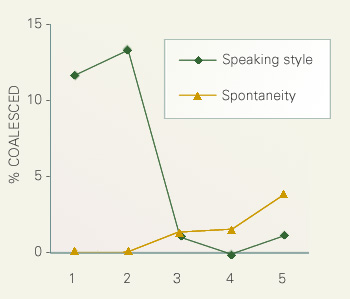
次の図は、融合率と印象評定された発話スタイルおよび自発性の関係を示しています。融合率は発話スタイルが上昇すると低下し、自発性が上昇すると上昇することがわかります。この関係も長母音の短呼現象の場合と一致しています。後に6-7で見るように印象評定データは言語変異の分析にとても有効なデータです。
|
| 6-6. 助詞「ノ」の撥音化 |
|
もうひとつ形態論レベルの変異現象として、助詞「ノ」が撥音「ン」に交替する現象をとりあげます。先に検討した語の融合現象では「デ」の品詞が融合率に強い影響を及ぼしていました。助詞「ノ」の撥音化においても品詞が重要な役割を果たしますが、今度は同じ助詞の内部における下位区分が問題になります。つまり、「本は机の上だ」>「ホンワツクエンウエダ」のように「ノ」が格助詞である場合と、「彼が東京に行ったのだ」>「カレガトーキョーニイッタンダ」のように準体助詞である場合です。下の表から格助詞と準体助詞の差が撥音化率にきわめて強い影響を及ぼしていることを示しています。
| ノの品詞 |
講演タイプ |
ノの生起数 |
ンの生起数 |
撥音化率 |
| 格助詞 |
学会講演 |
20598 |
75 |
0.4% |
| 模擬講演 |
11473 |
71 |
0.6% |
| 準体助詞 |
学会講演 |
4097 |
2681 |
39.6% |
| 模擬講演 |
4077 |
6045 |
59.7% |
|
(笑)の影響も検討してみましょう。語の融合の場合と同じく(笑)にも強い効果が認められます。
| ノの品詞 |
(笑) |
ノの生起数 |
ンの生起数 |
撥音化率 |
| 格助詞 |
無し |
31708 |
142 |
0.4% |
| 有り |
363 |
4 |
1.1% |
| 助動詞 |
無し |
7975 |
8305 |
51.0% |
| 有り |
199 |
421 |
67.9% |
|
さらに主観評定値(発話スタイルおよび自発性)とも明白に相関しています。下の図が示しているように、品詞の別によらず撥音化率はスタイルの上昇につれて低下し、自発性の上昇につれて上昇します。
|
| 6-7. 複合境界音調 |
|
コアのイントネーションラベリング作業は現時点(2003年3月)ではまだ完了していません。完了予定は2003年の6月です。ここでは、現在までにラベリングが終了したデータを利用して、2種類の複合境界音調の分布を比較してみました。複合境界音調とは、韻律的な句の末尾に生じる局所的なイントネーションです。自発音声には朗読音声よりも多彩な複合境界音調がより高い頻度で生じます。現在の X-JToBIではL%H% (ピッチの上昇), L%LH% (低ピッチが持続された後の上昇), L%HL% (上昇下降), and, L%HLH%(上昇下降上昇)という4種類の複合境界音調を認めています。
今回は、最も頻度の高い2種類の複合境界音調、L%H%とL%HL%の生起率を種々の要因との関係で調査しました。生起率は、ひとつの講演に含まれる対象音調の生起数を分子、その講演に含まれる2より強いBIの生起総数を分母として計算しています。X-JToBIのBIでは2+b, 2+bpのように2と3の中間値が定義されていますが、これらもすべて分母に含まれます。
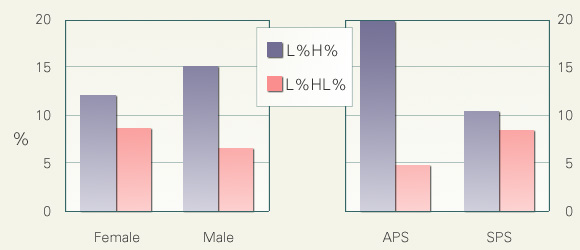
下の図では、話者の性差および講演タイプによってL%H%とL%HL%の生起率がどう変動するかを検討しました。二つの複合境界音調はちょうど反対のふるまいを示すことがわかります。すなわち、男性は女性よりもL%H%を、また女性は男性よりもL%HL%を多用する傾向にあります。また、学会講演にはL%H%がL%HL%よりも多く生じ、模擬講演にはL%HL%がL%H%よりも多く生じる傾向があります。
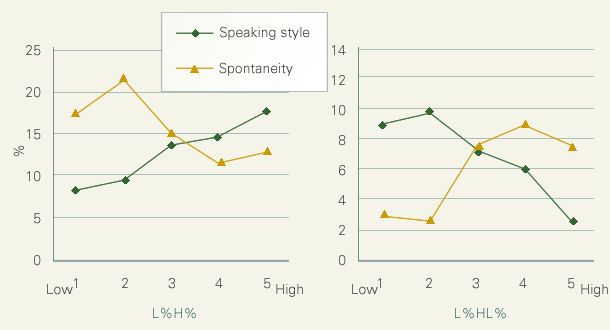
このような差は二つの複合境界音調が何らかの意味で発話スタイルと相関しているために生じるものだと思われます。そこで発話スタイルおよび自発性の印象評定値との関係を分析してみました。ここでもまたふたつの複合境界音調は正反対のふるまいを示しています。L%H%の生起率は発話スタイルが上昇すると上昇し、自発性が上昇すると低下するのに対し、L%HL%の生起率は発話スタイルが上昇すると低下し、自発性が上昇すると上昇しています。
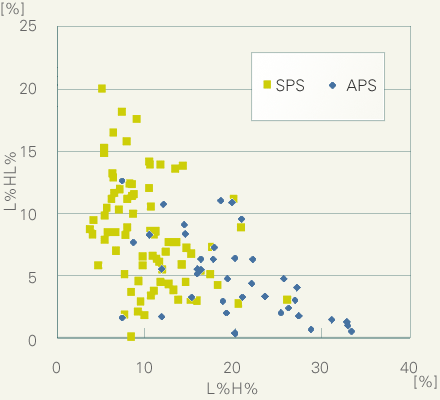
L%H%とL%HL%の生起率に観察されるこのような差異は、一定限度内であれば、音調を参照するだけで講演のタイプやスタイルを予測可能であることを示唆しています。そこでL%H%とL%HL%の使用率の散布図を作成してみました。このような単純な分析でも模擬講演と学会講演のタイプ差をかなり正確に判別できることがわかります。音調と発話スタイルの関係については、今後さらに詳細な研究が必要なことは言うまでもありませんが、統計的にみるかぎり、両者間に密接な関係が存在していることはほぼ間違いありません
|
| 6-8. 言語変異の要因 |
|
以上の予備的分析結果は、全体として『日本語話し言葉コーパス』が言語変異を研究するための優れた研究資源となりうることを示しています。以下の表に種々の言語変異現象と種々の要因の組み合わせについて一元配置の分散分析を適用した結果をまとめてみました。とりあげた要因のうち「タイプ」は学会講演と模擬講演の違いを、速度は転記基本単位毎に計算され話者毎に正規化された発話速度を、「スタイル」と「自発性」は主観評定された値を、それぞれ意味しています。この表を見ると、どの変異に関しても最低四つの要因が統計的な有意性をもって関係しており、また、発話速度を除けば、どの要因についても最低四つの変異現象が統計的に有意な差を示していることがわかります。なお全般的に非常に高い水準の有意差が生じていますが、これは『日本語話し言葉コーパス』のデータ量が非常に大きいことによるものです(生起数の欄参照)。
| 変異現象 |
生起数 |
FACTORS |
| タイプ |
速度 |
スタイル |
自発性 |
(笑) |
性別 |
| 母音の無声化 |
300,018 |
**** |
**** |
**** |
**** |
NS |
**** |
| 語彙的長母音の短呼 |
47,886 |
**** |
NS |
**** |
**** |
**** |
**** |
| 語の融合「ジャ」:格助詞の場合 |
1,730 |
**** |
NS |
**** |
*** |
*** |
NS |
| 語の融合「ジャ」:助動詞の場合 |
1,707 |
**** |
NS |
**** |
**** |
**** |
NS |
| 「ノ」の撥音化 |
32,317 |
** |
NS |
**** |
** |
NS |
**** |
| 「ノ」の撥音化 |
16,900 |
**** |
**** |
**** |
**** |
**** |
**** |
|
Significant at **** P<. 0001, *** P<. 001, ** P<. 01, NS P>=. 01
|
| 6-9. 品詞の主成分分析 |
|
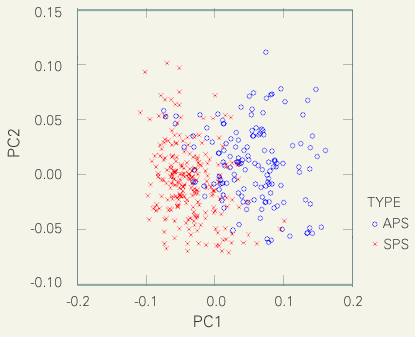
予備的分析を始めた直後から、学会講演と模擬講演では品詞の分布に組織的な差があることがわかっていました。相対的に言って学会講演では名詞や格助詞の比率が高く、模擬講演では形容詞や副詞の比率が高いのです。ここでは品詞分布のデータを主成分分析した結果を示します。下の図からは、最も大きなふたつの主成分(PC1, PC2)を利用するだけで、学会講演と模擬講演がきれいに分離されることがわかります。PC1 とPC2の寄与率はそれぞれ55%と20%です。つまりこれら二つの主成分でデータに含まれる分散の75%が表現されていま
|
|
7. 予備的分析のまとめ |
|
|
以上の分析はいずれも予備的なものです。それにもかかわらず、これらの分析は『日本語話し言葉コーパス』が従来にない日本語の音声言語データベースとなっていることを充分に示していると思います。
|
|
|