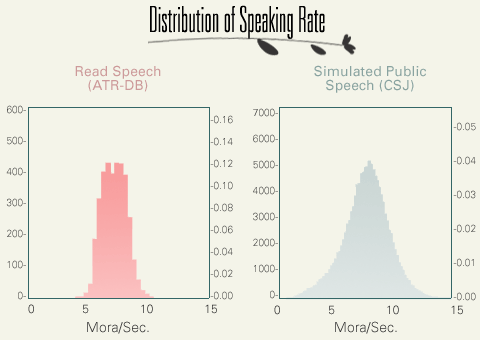
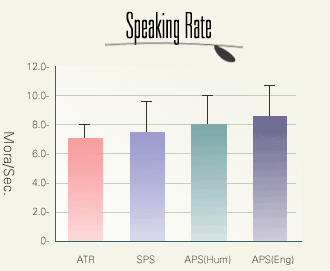
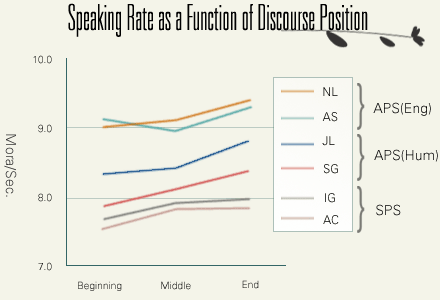
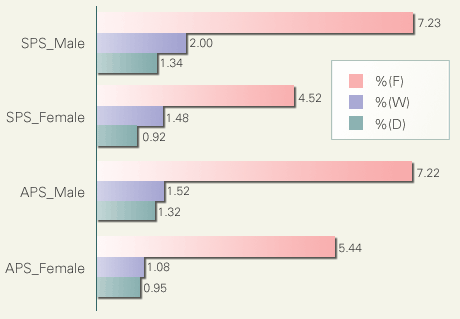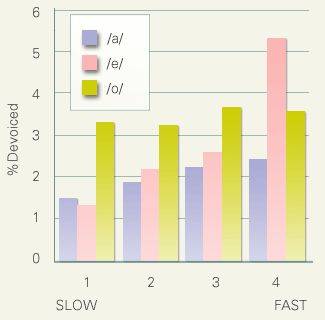ここからは言語変異現象の分析に入ります。最初に母音の無声化をとりあげますが、この現象は音声レベルの変異、つまり、語の意味に影響をおよぼすことのない変異現象です。
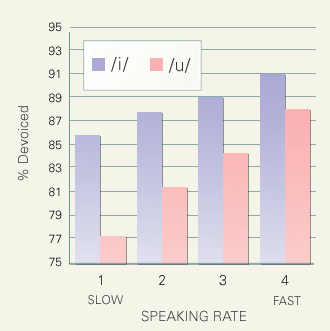
日本語の狭母音(/i/と/u/)は前後を無声子音に囲まれると無声化する傾向があります。この傾向は共通語の母体となった東京方言では特に顕著に現れます。そのため東京語に関する音韻分析では、無声母音を通常の有声母音の条件異音と見なす分析もおこなわれていますが、このような分析は過度に単純化されたものと言わなければなりません。何故ならば狭母音の無声化率は環境によって大幅に上下するからです。
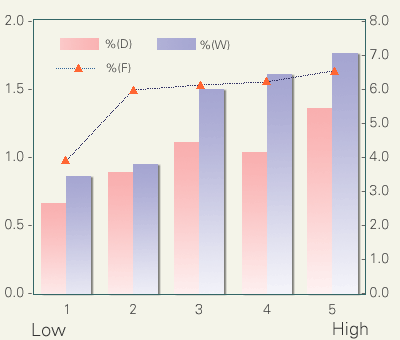
以下の表は狭母音に隣接する無声子音の調音様式が無声化率におよぼす影響を示しています。コアのうち2002年夏の時点で分節音ラベルが付与されていた427,973個の母音(五母音全体、狭母音だけならば約20万個)を分析対象に用いました。
狭母音に摩擦音が後続すると無声化率が顕著に低下していることがわかります。これはおそらく、この環境で母音が無声化すると、音声学的には無声摩擦音の連続が生じるため、モーラ境界の知覚が非常に困難になるためかと思われます。
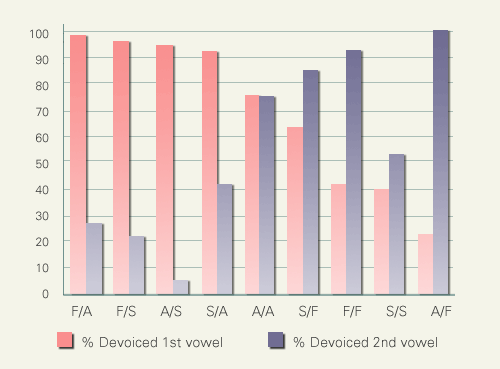
無声化率を低下させるもうひとつの要因に無声化の連鎖があります。つまり連続するふたつ以上のモーラ中の母音がすべて前後を無声子音に囲まれている環境です。以下の図はふたつのモーラが無声化連鎖環境におかれた場合の無声化率を検討したものです。横軸は対象とする狭母音を挟む子音の調音様式の組み合わせを示しています。記号F, A, Sはそれぞれ摩擦音、破擦音、破裂音を意味します。
ここでもまた、調音様式の組み合わせが重要な役割を果たしています。最初のモーラに含まれる母音の無声化率に注目すると、無声化率が高く保たれるのは、後続する子音が破裂ノイズで始まるタイプ(つまり破裂音か破擦音)の場合です。反対に後続子音が摩擦音であると第1母音の無声化率は低下し、代わりに第2母音の無声化率が上昇します。