 |
 |
| 5-1. Transcription and tag |
|
Recorded speech is transcribed in two different ways: orthographic and phonetic transcriptions.
In "orthographic" transcription, speech is transcribed using Kanji (Chinese logograph) and Kana (Japanese syllabary) just like ordinary Japanese text, but unlike the ordinary Japanese writing, our orthographic transcription has rigorous rules about the usage of Kanji and Kana letters. In ordinary text, for example, there are more than five ways of transcribing the phonemic string of /hanasiai/ ("meeting") using Kanji and Kana, but in our orthographic transcription, only one is allowed. Orthographic transcription is useful in making queries of text.
"Phonetic" transcription is written exclusively in Kana letters so that the phonetic details of the utterance being transcribed can be traced. Phonetic transcription is needed for two main purposes. For one, it specifies the reading of many Kanji strings that have multiple readings. For another, it is useful for the study of phonetic/phonological variations of spontaneous speech.
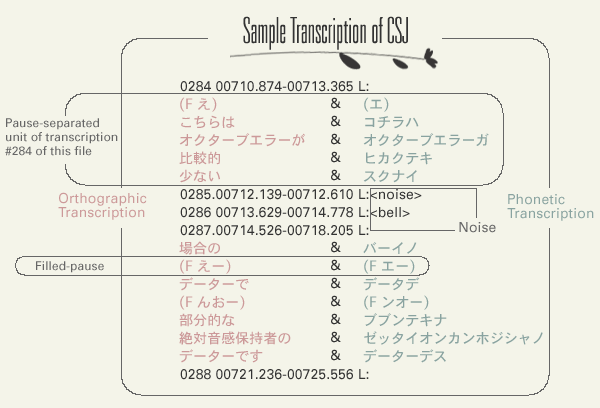
The following table shows examples of the tags used in the transcription text.
| Type I: Tags that refer to the characteristics of linguistic message |
| Tag |
Usage |
Example |
| (D) |
Word fragment, repairs |
(D ko) korewa |
| (W) |
Reduced or incorrect pronunciation |
(W midari; hidari)** |
| (?) |
Uncertainty |
(? taonguH) |
| (F) |
Filled pauses |
(F anoH) |
| (M) |
Meta-linguistic expression |
(M wa) wa (M ha) to kaku |
| (O) |
Foreign language, archaic Japanese etc. |
(O zaQcu FaiN)
"That's fine" |
| (A) |
Use of alphabet in orthographic transcription |
(A iHuH; EU)*** |
| (K) |
Exceptional use of Kana in orthographic transcription |
(K taci (F N) bana; XX)
XX stands for Kanji letter of /tacibana/ |
(Laugh)*
(Cry)
(Cough)
(Yawn) |
Speaking while laughing
Speaking while crying
Speaking while coughing
Speaking while yawning |
(Laugh heNnano) |
| (L) |
Whispery voice |
- |
| Type II: Tags that refer to the existence of phonetic / non-verbal events |
| <H> |
Non-lexical lengthening of vowels |
sorede<H> [sorede:] |
| <Q> |
Non-lexical lengthening of consonants |
kai<Q>seki [kais:eki] |
| <FV> |
Vowel whose phonemic status is not identifiable |
sorede<FV> |
<Breath>*
<Laugh>
<Cry>
<Cough> |
Breathing noise
Laughter (not speaking)
Cry (not speaking)
Cough (not speaking) |
aru wake desu <Breath> |
|
* The tag letters in this cell are Kanji.
** Entity to the left of ';' is incorrect. Entity to the right is supposed-to-be correct form.
*** Entity to the left of ';' is written in Kana. Entity to the right is in alphabet letters. |
| 5-2. POS information |
|
Two different POS systems were prepared for CSJ: short-unit word (SUW) and long-unit word (LUW). Most of the SUW are mono-morphemic words or words made up of two consecutive morphemes, and approximate dictionary items of ordinary Japanese dictionaries.
LUW, on the other hand, is for compounds. For example, the Japanese name for NIJLA is /kokuricukokugokenkyuHzyo/, where /kokuricu/ ('national'), /kokugo/ ('Japanese'), /kenkyuH/ ('research'), and, /zyo/ ('institution') are all SUW. These four SUW make up a single LUW. Although most LUW are the combinations of consecutive noun SUW or verb SUW, there are cases where combinations of particles or combination of a particle and a verb make up a LUW. For example, a LUW /niyoQte/ ('by') is the combination of a particle /ni/ (place particle) and a verb /yoru/ ('due to').

|
| 5-3. Impressionistic rating |
|
During the course of recording, one of recording engineers evaluated subjectively the speech being recorded. This is necessary because the speaking style and spontaneity of speech differ considerably from speech to speech even within a single category of speech (APS for example).
A Five-scale rating was used for the evaluation of the following characteristics: 1) spontaneity, 2) field-specific technical terms, 3) speaking rate, 4) clearness of speech articulation, 5) dialectal features (in terms of lexicon, segmental sound, and lexical accent), and 6) speaking style.
In addition to the above, we prepared a list consisting of 31 evaluation words and used it to evaluate the overall impression of the speech. The list contained words like "fluent", "disfluent", "monotone", "expressive", "relaxed", "tense", and so forth. |
| 5-4. Segment label |
|
The Core of the CSJ is segment labeled. The labels are basically phonemic, but some phonetic labels are used, too. Phonetic labels are introduced for the study of phonetic variation and spontaneous speech-specific phenomena.
The phonemic labels were generated automatically from the phonetic transcription, and were aligned automatically to speech signals using a Hidden Markov Model-based algorithm. Human experts, then, adjusted the location and category of automatically generated labels.
|
| 5-5. Intonation label |
|
The Core is also intonation labeled. Because the intonation of spontaneous Japanese differed considerably from that of the read speech, we newly proposed an extended version of the traditional J_ToBI scheme. The new scheme is called X-JToBI. In the new scheme both the tone and BI (boundary index) labels were considerably extended to match the paralinguistic features of the spontaneous speech intonation. Here are some examples of the X-JToBI extensions.
- Enlargement of the phrase-final boundary tone: Two new boundary pitch movement (BPM) categories, i.e., L%LH%, L%HLH%, were added to the traditional two, i.e., L%H% and L%HL%.
- Time-decomposition of complex boundary tones: Complex boundary tones like L%HL% are decomposed into their constituent labels, L%, pH, and HL% in this case, and each of the constituent labels has it is own time stamp. The 'pH' label is called "pointer" and used to denote the peak in the F0 contour. Similarly, L%LH% is decomposed into L%, pL, and LH%. In this way, an exact match between the tone labels and their corresponding F0 event was assured.
- Enlargement of the BI inventory: New BI labels were introduced to denote prosodic boundaries caused by the occurrence of various disfluency phenomena like filled-pauses, fragmented word, word-internal pause. BI labels were also enlarged so that they could represent intermediate strength of the prosodic boundary. For example, the labels like "2+b" and "2+bp" stand for the prosodic boundary whose strength is in between the traditional "2" and "3". The alphabet letters in these labels denote the "reasons" why the strength of the boundary in question was judged to be intermediate. For example, "2+b" is used for the cases where an accentual phrase ends with a BPM, not followed by a pause, and, pitch range resetting was not observed across the boundary in question. Similarly, "2+bp" is applied for the cases where an accentual phrase ends with a BPM, followed by a pause, and, pitch range resetting was not observed.
|
| 5-6. Miscellaneous annotations |
|
The annotations explained so far were all in the blueprint of CSJ. Prompt progress of the compilation, however, made it possible to add some new annotations to the Core. The new annotations include, 1) Discourse structure, 2) Sentence-like syntactic boundary, and, 3) dependency structure. These annotation are currently underway at CRL. See the linked documents for details.
|
|
|



