中納言マニュアル:検索条件式
検索条件式とは
検索条件式は、「検索条件式で検索」タブをクリックして表示される入力欄に記入する条件の記述方法です。 フォームで指定する検索条件と同等の内容を条件式で記述することができます。 条件式では、フォームでは指定できない細かな条件を指定することも可能です。
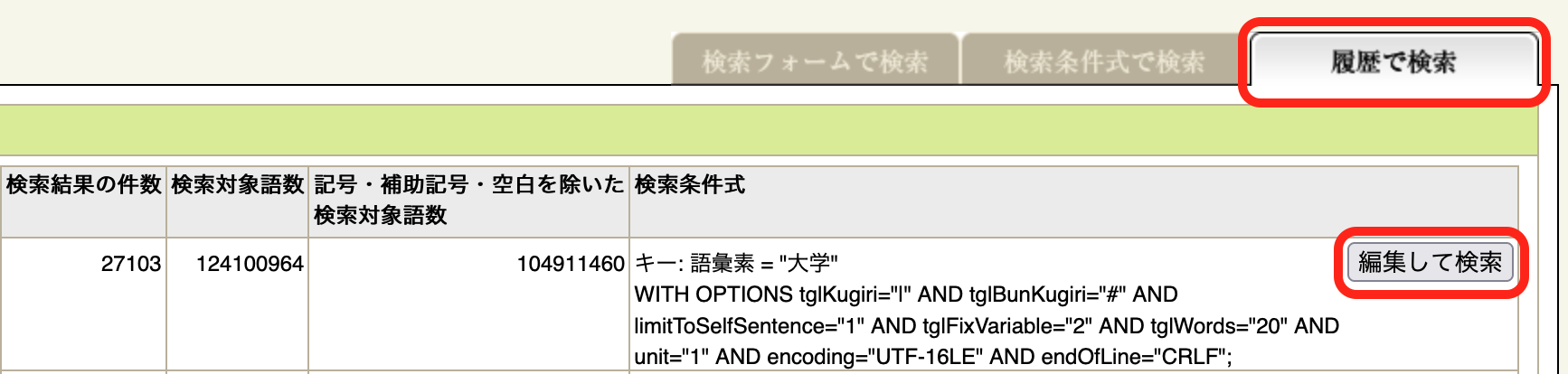
中納言内部では、 「検索フォームで検索」で指定した検索条件は、検索条件式に変換されて検索に利用されて います。「履歴で検索」タブにある検索履歴に記載されているのはこの条件式です。
検索式の例
「語彙素 = "大学"」に一致する語をキーとして検索
検索を実行をすると「履歴で検索」タブにある検索履歴に条件式が追加されます。以下は、例1の条件式を 実行した後の検索履歴です (WITH OPTIONS以下は画面上のフォームの設定が自動的に追加されています)。 「編集して検索」ボタンをクリックすると 履歴の条件式を編集して検索条件式による検索を行うことができます。
検索式の基本構造
検索式は「キー条件 and/or 共起条件」と「任意の追加条件」で構成されます。 任意の追加条件には、「コーパス条件」、「出版年条件」、「対象者条件」、「その他の条件」、 「出力ファイル名」があります。
|
[SEARCH] キー条件 and/or 共起条件 [IN コーパス条件] [PUBLISHED IN 出版年条件] [対象者条件] [WITH OPTIONS その他の条件] [OUTPUT INTO 出力ファイル名] |
角括弧 [ ] は省略可能を表します(実際の検索式には角括弧は書きません)。
キーワードとキーワードの間は半角スペースまたは改行(両者は内部処理では区別されません)で区切ります。
キー条件の書き方
キーの指定は、例1や以下の例のように「キー」 というキーワードの後ろにコロン(:)を入れ、その後にキーの条件を指定します。
「書字形出現形 = "珈琲"」に一致する語をキーとして検索
キー: 書字形出現形 = "珈琲"
条件の左の項(上記では「書字形出現形」)には、検索の種類にあわせて語彙素の属性などを指定できます。 右の項には二重引用符で囲んだ文字列(上記では「"珈琲"」)を指定します。
条件に指定できる属性
検索の種類によって条件の左項に指定できる属性は異なります。
短単位・長単位検索で左項に指定可能な属性

単位検索で、「書字形 = "はしる"」に一致する語をキーとして検索
キー: 書字形 = "はしる"
文字列検索で左項に指定可能な属性

文字列検索で、「お腹が減った」を検索
キー: 全文検索 @@ "お腹が減った"
位置検索で左項に指定可能な属性

条件の書き方(完全一致・部分一致・全文検索)
条件は完全一致、部分一致、全文検索があります。
| 条件の種類 | 記号 | 例 |
|---|---|---|
| 完全一致 | = | 語彙素 = "大学" |
| 部分一致 | LIKE | 語彙素 LIKE "%学校" |
| 全文検索 | @@ | 全文検索 @@ "おなかが減った" |
部分一致、全文検索では、ワイルドカード を使った検索を行うことができます。
単位検索で、語彙素が「学」終わる語をキーとして検索
キー: 語彙素 LIKE "%学"
単位検索で、語彙素が「小学」「中学」「大学」のいずれかの語をキーとして検索
キー: 語彙素 LIKE "[小中大]学"
文字列検索で、「(腹以外の文字)が減った」を検索
キー: 全文検索 @@ "[^腹]が減った"
キーの条件を複数書く(AND / OR / NOT)
複数の条件を指定する場合は、AND、OR、NOTを指定し、適宜括弧を使用します。
単位検索で、「品詞が名詞で始まり」かつ「語彙素が学で終わる」かつ「語彙素が大学で終わらない」に一致する語をキーとして検索
キー: (品詞 LIKE "名詞%" AND 語彙素 LIKE "%学" AND NOT 語彙素 = "大学")
位置検索で、「サンプルID = "PM51_00766"」 かつ 「開始番号 = "12280"」に一致する語をキーとして検索
キー: (サンプルID = "PM51_00766" AND 開始位置 = "12280")
迷ったら括弧 ( ) を付けると安全です。
共起条件
共起条件は、キーの前後に現れる語や条件を指定して絞り込むものです。 キーに対して前の条件を「前方共起」、後ろの条件を「後方共起」と呼びます。
前方共起(キーの前にある語)
「前方共起」というキーワードの後にコロン(:)を入れ、その後に条件を指定します。
キー「語彙素 = "大学"」の1つ前に「語彙素 = "国立"」がある条件
キー: 語彙素 = "大学" AND 前方共起: 語彙素 = "国立" ON 1 WORDS FROM キー
キーの条件を指定せず、後方共起、前方共起だけを指定することもできます。
キーの条件を指定せず、キーの1つ前に「語彙素 = "国立"」がある条件
前方共起: 語彙素 = "国立" ON 1 WORDS FROM キー
後方共起(キーの後にある語)
「後方共起」というキーワードの後にコロン(:)を入れ、その後に条件を指定します。
キー「語彙素 = "大学"」の1つ後ろに「語彙素 = "に"」 がある条件
キー: 語彙素 = "大学" AND 後方共起: 語彙素 = "に" ON 1 WORDS FROM キー
共起条件で指定できる範囲(ON / WITHIN)
共起条件を指定する場合は、条件の範囲を指定する必要があります。指定は、以下の順で行います。
| (位置・範囲指定) (正の整数) WORD FROM (基準位置) |
位置・範囲指定:ON と WITHIN のいずれかを指定
- ON:キーから何語目にあるか(位置指定)
- WITHIN:キーから一定範囲内(範囲指定)
基準位置に指定可能な項目
キーの後ろ3語以内に「語彙素 = "に"」がある
キー: 語彙素 = "大学" AND 後方共起: 語彙素 = "に" WITHIN 3 WORDS FROM キー
コーパス条件(IN)
キーワード IN を使うと、検索対象レジスターやジャンルを絞ることができます。
「出版・新聞」のレジスターだけで「語彙素 = "大学"」を検索する
キー: 語彙素 = "大学" IN registerName = "出版・新聞"
主な指定項目
検索対象の範囲に指定できる項目は、コーパスによって異なります。 たとえば、BCCWJでは以下の項目を指定することができます。
- registerName(レジスター)
- GENRE(ジャンル)
- core(コア)
複数条件を組み合わせる。レジスター(出版・新聞)、コア、ジャンル1(全国紙)、ジャンル2(朝日新聞)
キー: 語彙素="大学" IN (registerName="出版・新聞" GENRE GENRE1="全国紙" GENRE2="朝日新聞" AND core="true")
出版年条件(PUBLISHED IN)
出版年など、年代情報で検索対象を限定する場合は、PUBLISHED INキーワードを使用します。
1975年のデータに限定する
キー: 語彙素="大学" PUBLISHED IN 1975
複数の年を指定する場合は、対象の年を半角スペースで区切って列挙します。
1975~1979年のデータに限定する
キー: 語彙素="大学" PUBLISHED IN 1975 1976 1977 1978 1979
その他の条件(WITH OPTIONS)
WITH OPTIONSは、検索結果の表示や出力形式などを調整するためのオプションです。
よく使うオプション
- tglWords(前後の表示語数)
- endOfLine(改行コード)
- encoding(文字コード)
前後文脈を15語表示する
キー: 語彙素 = "大学" WITH OPTIONS tglWords="15"
検索結果の出力ファイル名(OUTPUT INTO)
検索結果をファイル出力する際のファイル名は、OUTPUT INTOで指定できます。 ファイル名に使える文字は英文字、数字と - _ . (ハイフン、アンダーバー、ピリオド)です (ファイル名には二重引用符は付与しません)。
検索結果を出力するファイル名を指定する
キー: 語彙素 = "大学" WITH OPTIONS encoding="UTF-16LE" AND endOfLine="CRLF" OUTPUT INTO result_university.csv;
上記の検索条件式を入力して「検索結果をダウンロード」ボタンをクリックすると、 result_university.csv というExcelで表示可能なファイルで検索結果がダウンロードされます。 (拡張子を .csv としているのは、Excelで利用しやすくするためで、中身はタブで区切られたテキストファイルです。)
よくある間違い(FAQ)
付録:検索条件式の詳細(EBNF)
EBNFとは
EBNF は構文規則を表す記法です。ここでは EBNF で検索条件式の仕様を示します。 EBNF で使われる主な記法の意味は以下の通りです。
| 記法 | 説明 |
|---|---|
| = | 定義(左辺が名称、右辺が定義内容) |
| [ ] | 中の記述は省略可能 |
| { } | 中の記述を0回以上繰り返し |
| ( ) | グループとして扱う |
| | | または |
| ? ? | 特殊な文字列 |
| " " | 文字列そのもの |
| , | 文字列の連結 |
検索条件式群と検索条件式
検索条件式群(conditions)は複数の検索条件式(condition)をセミコロンで区切ったものです。 EOF は入力の終わりを示します。
検索条件式(condition)は共起条件(cooccurrence or clause)にコーパス条件、出版年、その他の条件、出力ファイル名を組み合わせたものになります。
| 指定条件 | 定義名 | 記述方法 | |
|---|---|---|---|
| コーパス条件 | corpus condition item | IN ... | 省略可能。定義の詳細はコーパス条件を参照 |
| 出版年 | published years | PUBLISHED IN ... | 省略可能。西暦で指定。複数指定する場合は空白で区切る |
| その他の条件 | search option set | WITH OPTIONS ... | 省略可能。定義の詳細はその他の条件を参照 |
| 出力ファイル名 | filename | OUTPUT INTO ... | 省略可能。定義の詳細は文字列などを参照 |
conditions = { ";" }, condition, { { ";" }, condition }, { ";" }, EOF
condition = [ "SEARCH " ],
cooccurrence or clause,
[ " IN ", corpus condition item ],
[ " PUBLISHED IN ", published years ],
[ " WITH OPTIONS ", search option set ],
[ " OUTPUT INTO ", filename ],
( EOF | ";" )
共起条件
共起条件(cooccurrence or clause)では複数の条件を連結したり、条件の否定を書くことが可能です。
| 指定条件 | 定義名 | 記述方法 | |
|---|---|---|---|
| または | cooccurrence or clause | ... OR ... | ANDより演算順序は後 |
| かつ | cooccurrence and clause | ... AND ... | NOTより演算順序は後 |
| 以外 | cooccurrence not clause | NOT ... NOT(...) |
cooccurrence condition item を否定 cooccurrence or clause を否定 |
cooccurrence or clause = cooccurrence and clause, { " OR ", cooccurrence and clause }
cooccurrence and clause = cooccurrence not clause, { " AND ", cooccurrence not clause }
cooccurrence not clause = [ "NOT " ], cooccurrence condition item | [ "NOT" ], "(", cooccurrence or clause, ")"
cooccurrence condition item は、共起条件の種類や文中での位置、表示のオプションを組み合わせたものです。
| 指定条件 | 定義名 | 記述方法 | |
|---|---|---|---|
| 条件の種類 | cooccurrence condition item | 前方共起: ... キー: ... 後方共起: ... |
|
| 文中での位置 | lemma position condition | WITHIN △ WORDS FROM ○○ ON △ WORDS FROM ○○ |
○○から△語以内 ○○から△語 省略可能。○○には キー、文頭、文末 のいずれか。 |
| キーと連結して表示 | - | DISPLAY WITH KEY | 省略可能 |
| 検索方法 | lemma condition item | ○○ = □□ (完全一致) ○○ LIKE □□ (ワイルドカードを使用した場合) ○○ @@ □□ (全文検索) |
○○にはlemma condition property key □□には文字列 |
cooccurrence condition item = cooccurrence condition prefix, ":", lemma not clause, [ lemma position condition ], [ " DISPLAY WITH KEY" ]
cooccurrence condition prefix = "前方共起" | "キー" | "後方共起"
lemma position condition = lemma position condition prefix, positive number, "WORDS", "FROM", lemma position root
lemma position condition prefix = " WITHIN " | " ON "
lemma position root = "キー" | "文頭" | "文末"
lemma or clause = lemma and clause, { " OR ", lemma and clause }
lemma and clause = lemma not clause, { " AND ", lemma not clause }
lemma not clause = [ "NOT " ], lemma condition item | [ "NOT " ], "(", lemma or clause, ")"
lemma condition item = lemma condition property key, lemma condition
lemma condition property key = "書字形出現形" | "発音形出現形" | "品詞" | "活用型" | "活用形"
| "語彙素" | "語彙素読み" | "語形" | "語形代表表記" | "書字形" | "語種" | "全文検索"
lemma condition = " = ", quoted string | " LIKE ", quoted string | " @@ ", quoted string
注:lemma condition property key はコーパスによっては指定できないものがあります。
キー: (品詞 LIKE "名詞%" AND (語彙素 LIKE "%学校" OR 語彙素 = "高校" OR 語彙素 = "大学") ) AND 後方共起: ( 品詞 LIKE "助詞%" AND 語彙素 = "に" ) ON 1 WORDS FROM キー AND 後方共起: ( 品詞 LIKE "動詞%" AND ( 語彙素 = "行く" OR 語彙素 = "往く" ) ) WITHIN 10 WORDS FROM キー
この例は、以下の3つの条件すべて満たすものを表します。
- キーは、品詞が名詞(大分類)で、語彙素が「学校」で終わるか、語彙素が「高校」か、語彙素が「大学」
- キーの次の語が、品詞が助詞(大分類)で、語彙素が「に」
- キーから後方10語以内に、品詞が動詞(大分類)で、語彙素が「行く」あるいは語彙素が「往く」
キー: (品詞 LIKE "動詞%" AND 語彙素 = "減る") WITHIN 6 WORDS FROM 文末 AND 後方共起: (品詞 = "助動詞" AND 語彙素="た" ) WITHIN 4 WORDS FROM キー AND 前方共起: (品詞 LIKE "名詞%" AND (語彙素 = "腹" OR 語彙素 = "御腹")) WITHIN 6 WORDS FROM キー
この例は、以下の3つの条件すべて満たすものを表します。
- キーは、品詞が動詞で、語彙素が「減る」で、文末から6語以内。
- キーから後方4語以内に、品詞が助動詞で、語彙素が「た」
- キーから前方6語以内に、品詞が名詞で、語彙素が「腹」あるいは語彙素が「御腹」
コーパス条件
コーパス条件(corpus condition item)では、検索対象に含めるレジスターの指定を行えます。 コーパス条件でも、複数の条件を連結したり、条件の否定を書くことが可能です。 レジスターに対して、さらに詳細なジャンル指定を行うこともできます。
| 指定条件 | 定義名 | 記述方法 | |
|---|---|---|---|
| または | corpus or clause | ... OR ... | ANDより演算順序は後 |
| かつ | corpus and clause | ... AND ... | NOTより演算順序は後 |
| 以外 | corpus not clause | NOT ... NOT(...) |
一つのレジスターを除外 corpus or clause を否定 |
| ジャンル指定 | GENRE ... | 一つのレジスターに対して |
corpus condition item = corpus or clause
corpus or clause = corpus and clause, { " OR ", corpus and clause }
corpus and clause = corpus not clause, { " AND ", corpus not clause }
corpus not clause = [ "NOT " ], string, "=", quoted string, [ " GENRE ", genre or clause ] | [ " NOT " ], "(", corpus or clause ")"
genre or clause = genre set, { " OR ", genre set }
genre set = genre clause, { genre clause }
genre clause = string, "=", quoted string
その他の条件
その他の条件は、「文字列 = 二重引用符で囲まれた文字列」の形で指定する条件を、必要に応じて ANDで組み合わせたものです。
search option set = search option clause, { " AND ", search option clause }
search option clause = string, "=", quoted string| string | quoted string の中身 | 意味 |
|---|---|---|
| unit | 1, 2, 3, 4 | 検索種別。現在のページと異なっているとエラー。 短単位検索なら1、長単位検索なら2、文字列検索なら3、位置検索なら4 |
| tglKugiri | 文字列 | 区切りに使用する文字列 |
| tglBunKugiri | 文字列 | 文区切りに使用する文字列 |
| tglWords | 正の整数 | 前後文脈の語数 |
| limitToSelfSentence | 0, 1 | 共起条件の範囲。文境界をまたぐなら0、またがないなら1 |
| tglFixVariable | 0, 1, 2 | 検索対象。固定長なら0、可変長なら1、両方なら2 |
| keyDisplay | 0, 1, 2 | キー表示形式。語なら0、文字列全体なら 1 または 2 |
| resultUnitWord | short, long | 結果表示単位。短単位なら short、長単位なら long |
| targetString | 1, 2, 3 | 対象文字列。校訂本文なら 1, 原文なら 2 または 3 |
| encoding | UTF-8 UTF-16LE Shift_JIS EUC-JP |
文字コードの種類 |
| endOfLine | CRLF CR LF |
改行コードの種類 |
tglKugiri="+"
この例は、以下の条件を表します。
- 文脈中の区切り記号を + にして結果を表示
endOfLine="CRLF" AND encoding="UTF-16LE"
この例は、以下の条件を表します。
- ダウンロード時に Windows の Excel で処理できる形式で出力
文字列など
上で出現したその他の定義は以下のようになっています。
published years = publish year, { " ", publish year }
published year = single digit without zero, single digit, single digit, [ single digit ]
filename = ? Plain string with some symbols ?
quoted string = '"', ? Escaped string ?, '"'
string = ? Plain string without symbols ?
positive number = single digit without zero, { single digit }
single digit without zero = "1" | "2" | "3" | "4" | "5" | "6" | "7" | "8" | "9"
single digit = single digit without zero | "0"