言語コーパスガイダンス
言語コーパスとは何か、どのように役立つか
日本語をはじめとするさまざまな言語を分析するための基礎資料として、書き言葉や話し言葉の資料を体系的に収集し、研究用の情報を付与した言葉のデータベースを言語コーパス (language corpus)と呼びます。
コーパスは1960年頃から最初は言語研究のために構築されるようになりましたが、近年では狭い意味での言語学の領域を超えて、幅広い研究領域で利用されるようになってきました。また学術目的での利用だけでなく、産業界でも利用されています。
下の表は、コーパスがどのように利用されるかをまとめたものです。もちろん、このほかに、日本語に興味をもつ個人が、言葉に関する疑問を解消するためにコーパスを利用することも考えられます。
| 分野 | 利用目的 |
|---|---|
| 言語研究 | 言語学、日本語学、国語学など個別言語の研究 複数言語のコーパスの比較による対照言語学 |
| 情報処理 | 音声自動認識のための言語モデル、音響モデルの構築 自然言語処理のための言語モデルの構築 音声素片の編集に基づく音声合成 |
| 言語教育 | 外国人のための日本語教材開発 日本人のための教材開発 |
| 言語政策 | 常用漢字表を検討するための基礎資料 公用文表記法の見直しの基礎資料 |
| 辞書編纂 | 用例の検索 語の共起関係の把握 |
| 心理学 | 言語に関する実験の設計、刺激の統制 |
コーパスのつくり方
構築するコーパスの目的や用途により、つくり方はいろいろありますが、ここでは『現代日本語書き言葉均衡コーパス』を例につくり方を紹介します。
1. サンプリングの方法
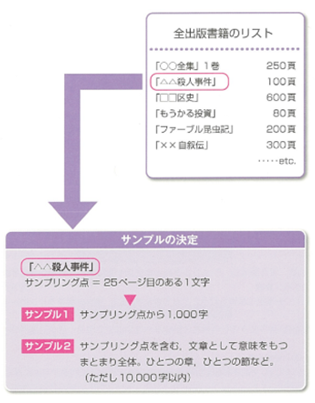
コーパスに採録するサンプルは無作為に選ばれます。
例えば書籍の場合、1986年から2005年の間に出版された書籍を対象として、そこから無作為に約30,000サンプルを選び出しました。
実際にサンプリング作業を行うと、ある本のあるページのある文字が選ばれます。これをサンプリング点と言います。
コーパスには、サンプリング点を含む2種類のサンプルを格納します。
2. サンプルの作成
1)コーパスに採録する部分を確定します
サンプリング点が決まったら、実際に採録するサンプルの範囲を確定します

2)著作権処理を行います
各サンプルについて、著作権処理を行います。使用許諾が得られなかったものは、採録されません。
3. サンプルの電子データ化
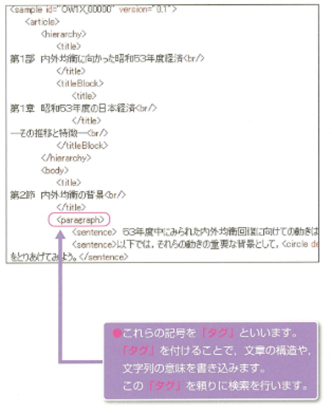
サンプルは「XML」というファイル形式で電子化します。
4. データの公開
構築された各コーパスは,次のような方法で順次公開されていきます。ただし,すべてのコーパスで以下の公開方法がとられるわけではありません。
- 無償オンライン公開(場合によっては要利用契約)
- 有償オンライン公開(要利用契約)
- データ全体の有償公開(DVD等による配布)
コーパスの公開と著作権
コーパスは広く公開されてこそ価値があります。そのため、コーパスの対象が現代語であり、著作権が消滅していない場合は、著作物の一部をコーパスに無償で利用させてもらう許諾を権利者からもらう必要があります。
『現代日本語書き言葉均衡コーパス』の場合は、著作権が消滅していない書籍・新聞・ウェブなどの文章から1億語以上のデータをサンプルとして集めました。構築したコーパスを広く活用していただくために、コーパスに採録するデータにはすべて著作権処理を施してあります。
検索用付加情報(アノテーション)
書き言葉コーパスのもっとも単純な形は、テキスト(サンプルを構成する文字列)だけから構成される"テキストコーパス"です。正規表現を用いて単純な条件から複雑な条件の文字列まで検索することができます。
しかし、例えば「分かち書き」という語が「分かち書き」「分ち書き」「わかち書き」「分かちがき」「分ちがき」「わかちがき」「別ち書き」と複数の表記で表されている場合、テキストコーパスでは「分かち書き」の一語としてまとめあげることはできません。そこでコーパスに検索用情報を付加する必要が出てきます。この作業をアノテーションと呼びます。
日本語の基本的なアノテーションは、次のような「形態素解析(品詞アノテーション)」となります。
- テキストを「語」に分解すること
- 分解された語の品詞を確定すること
- 語がもちうる表記のゆれの範囲を知って、語の同一性を決定すること
形態素解析以外にも係り受け構造のアノテーションや述語項構造(主語・目的語・述語)のアノテーション、話し言葉では音声から文字への転記・音素・イントネーションのアノテーションなどがあります。
大規模コーパスの構築ではアノテーションの自動化が必須となります。形態素解析については、国立国語研究所と千葉大学が共同開発した形態素解析辞書UniDicや形態素解析器の技術向上により、実用上さしつかえのない水準に達しています。
日本語コーパスの未来
今後はコーパスを用いた言語研究により、言語政策や言語教育の世界で、従来は有識者と呼ばれる人たちの見識にゆだねられてきた判断に客観性を導入することができるようになります。
言語の基礎研究では、言語の構造よりも用法を重視した研究、言語の定量的側面を重視した研究、言語を孤立したシステムと見るのではなく、書き手・話し手や社会的文脈との関係を重視した研究が促進されることでしょう。
これからのコーパスはインターネットと結びつくことによって、数十億、数百億語規模にまで発展していくでしょう。そのような場合、研究者がデータ全体に目をとおすことは実際上不可能ですから、自然言語処理技術や統計的データ解析の技術をもちいて、データを自動分類することが必要になっていきます。結果としてコーパスは、人文科学的な言語研究と理工学的な言語研究の垣根をとりはらう効果をもつことになっていくでしょう。