
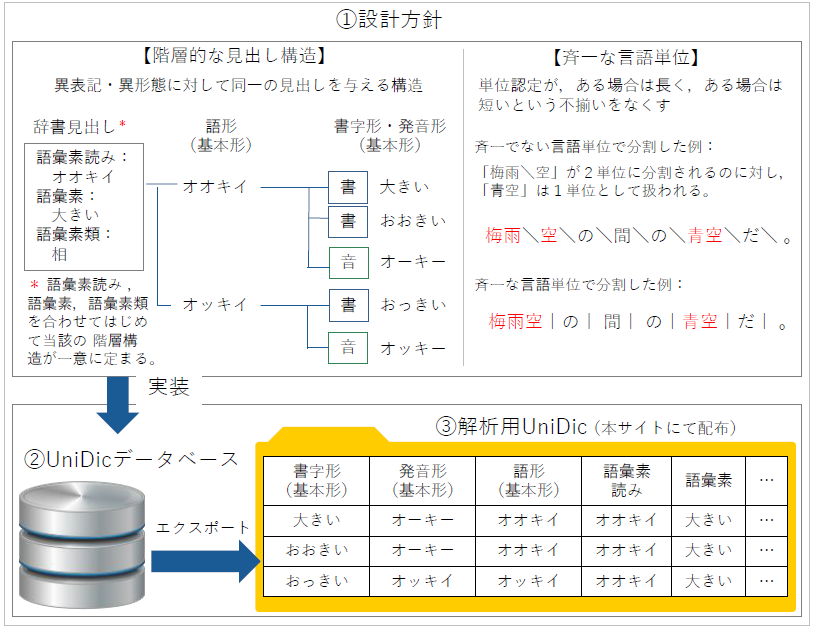
UniDicの第一の目的は、国語研で構築しているコーパスアノテーションを支援することです。
国語研所内にあるUniDicデータベースは、同じく所内のコーパスのデータベースと参照関係にあり、 完成したコーパスデータベース中の短単位は、
- UniDicデータベースに登録されており、
- UniDicデータベース中の一意のエントリを参照する(リンク付けられている)状態になっています。
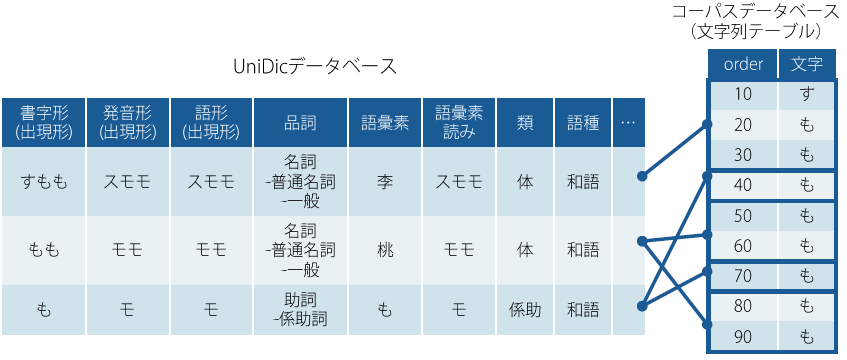
こうしたコーパスと辞書を統合したシステム運営の利点として、以下の2点が挙げられます。
- コーパスへの短単位情報アノテーションの際、作業は、 「コーパスに出現した各短単位がUniDicデータベースのどのエントリであるかを選択していけばいいだけ」なので、 コーパス中の異なる位置に出現した同一の短単位に対して、活用など、一部の情報を異なって付与してしまうミスを防ぎ、 コーパス中に不整合が生じる可能性を少なくできる。
- 現時点のUniDicデータベースに存在しない情報・属性(項目)が、新たにUniDicデータベースへ追加された場合でも、 データベース間のリンクでコーパスへの反映(新項目の追加)は瞬時に行える。
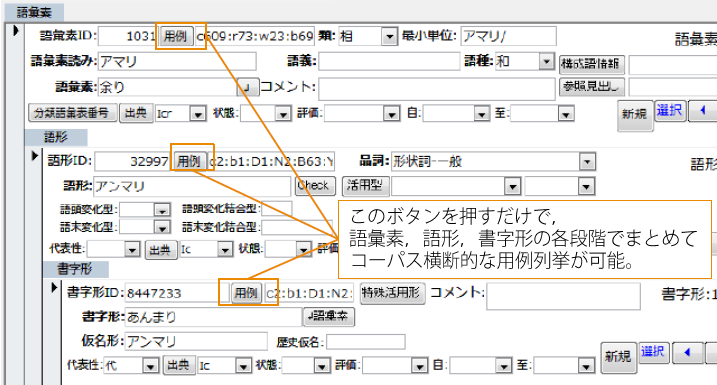
またコーパスデータベースとの参照関係の最大の利点は、UniDicデータベースの1エントリからコーパス中の膨大な用例を一度に引き出せる 用例索引の能力にあります。 下図に示す『UniDicExplorer』というUniDicデータベース用の操作ツールを使うと、 データベース中の短単位エントリを指定して用例列挙のボタンを押すだけで、 そのエントリに対応する用例を、コーパスデータベースから、 語彙素・語形・書字形の段階ごとに一覧して取得する事ができます。
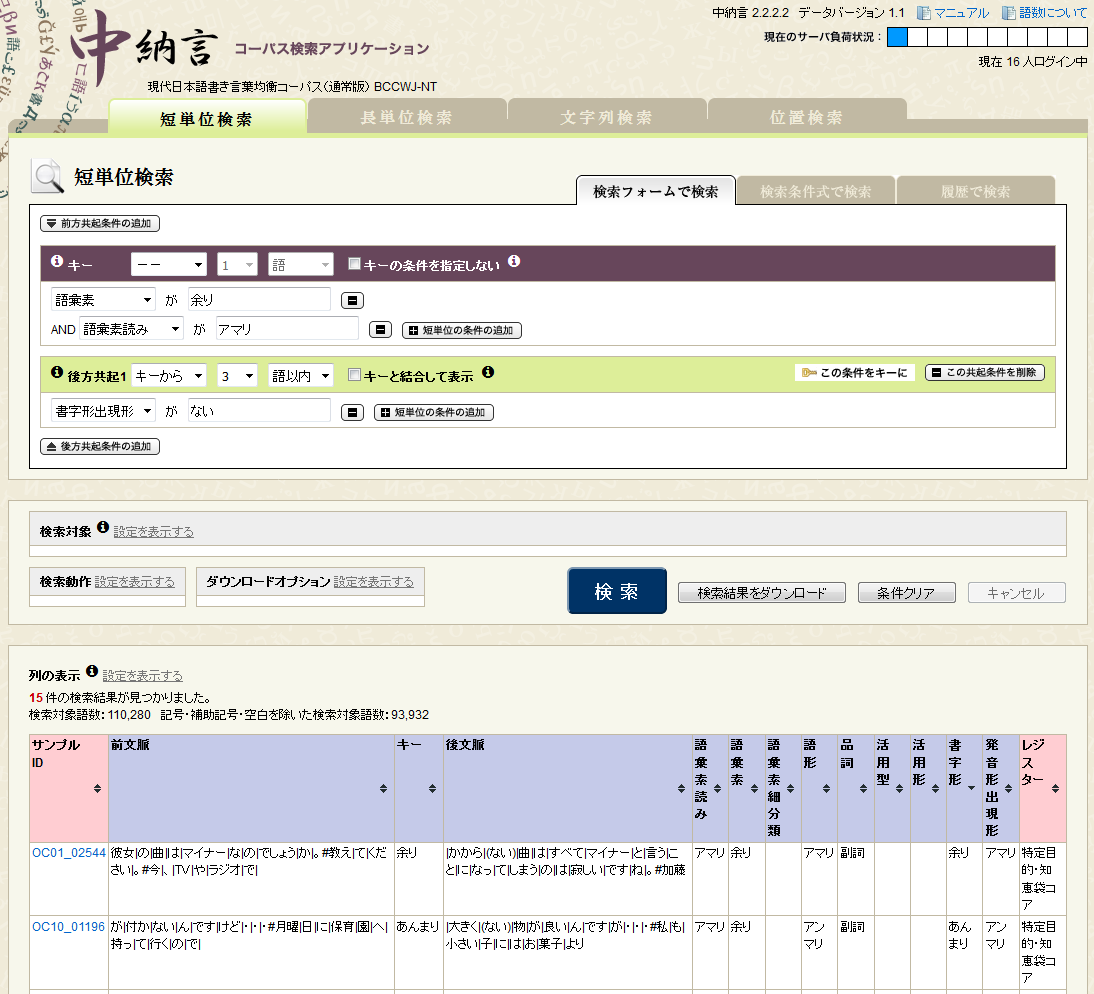
残念ながら現在、研究所外部のユーザに対して、 UniDicExplorerを使った所内コーパスデータベースへの直接アクセスサービスは提供していません。 しかし公開済みのコーパスならば、コーパス検索システム『中納言』を使うことで、 共起や連接の指定など、より柔軟かつ簡単な用例検索を行うことができます。
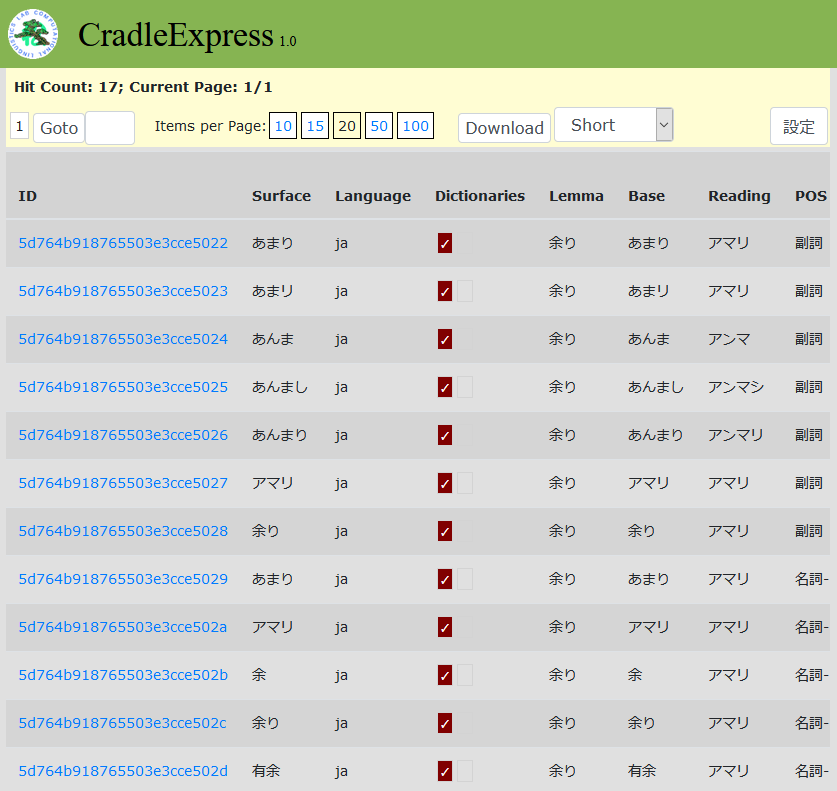
またUniDicDBではありませんが、解析用UniDic内蔵の語彙ファイル(lex.csv)を検索するサービスとしてCradleExpressがあります(2019年11月現在、unidic-cwj-2.3.0のlex.csvを検索可能)。
上述の通り、UniDicの第一の目的は国語研で構築するコーパスアノテーションを促進することです。 解析用UniDicも元々は『日本語話し言葉コーパス(CSJ)』の (i) 短単位自動アノテーションデータ(非コアデータ)を作成するために 構築されたのが始まりです。 『現代日本語書き言葉均衡コーパス(BCCWJ)』構築時からは 「解析用辞書を使った短単位自動解析の結果を人手修正していく」 という作業方針が採られるようになり、 現在では (ii)人手アノテーション作業のコスト削減ツールとしても利用されています。
本サイトで公開している解析用UniDicも、上記2つの用途 (i、ii)を意図しています。 下の参考文献「解析器用UniDicに関する論文」中に記載の解析性能も、 自動アノテーションで作ったコーパスの精度および、解析用UniDicのユーザが同様のコーパスを作ろうとしたときの 参考値(=どのくらい同じようなものが再現できるかの度合い)として掲載されています。
また短単位は、漏れの少ない 用例検索を重視した設計(単位の長さ、可能性に基づく品詞体系語源主義に基づく脱文脈化) となっているため、自然言語処理分野の統語解析や意味解析に向いていません。
統語解析には、構文機能に着目し、文節からトップダウンに認定する長単位の使用を推奨しています。
反面、用例検索に向けた斉一な単位であるため、文脈の有無や、文脈の違いによらず、一貫した自動解析を実現でき、 検索エンジンのような情報検索システム上で有効性があるとの報告もあります[高橋+, 16]。
| 名称 | URL | 参考URL |
|---|---|---|
| Bing | https://www.bing.com/ | https://help.bing.microsoft.com/apex/index/18/ja/10018 |
| 形態素解析ウェブアプリUniDic-MeCab(複合名詞判定,サ変動詞判定ver付き) | http://www4414uj.sakura.ne.jp/Yasanichi1/unicheck/ | http://www4414uj.sakura.ne.jp/Tools_unicheck.html |
| 形態素解析ウェブアプリUniDic-MeCab中学校教科書まとめ表現登録版 | http://www4414uj.sakura.ne.jp/Yasanichi1/sumex/ | http://www4414uj.sakura.ne.jp/Tools_sumex.html |
| Sudachi | https://github.com/WorksApplications/Sudachi | |
| mecab-unidic-NEologd | https://github.com/neologd/mecab-unidic-neologd | |
| UniDic Lite | https://pypi.org/project/unidic-lite/ | |
| UniDic2UD | https://pypi.org/project/unidic2ud/ | |
| konoha | https://github.com/himkt/konoha/ | https://github.com/himkt/konoha/releases/tag/v4.6.5 |
- 伝 康晴, 浅原 正幸: 「リレーショナル・データベースによる統合的言語資源管理環境」, 第1回『話し言葉の科学と工学』ワークショップ講演予稿集, pp.77-84 (2001).
- 伝 康晴, 小木曽 智信, 小椋 秀樹, 山田 篤, 峯松 信明, 内元 清貴, 小磯 花絵: 「コーパス日本語学のための言語資源:形態素解析用電子化辞書の開発とその応用」, 日本語科学, Vol.22, pp.101-123 (2007).
- 小木曽 智信, 中村 壮範: 「『現代日本語書き言葉均衡コーパス』形態論情報アノテーション支援システムの設計・実装・運用」, 自然言語処理, Vol.21, No.2, pp.301-332 (2014).
- 小木曽 智信, 中村 壮範: 「『現代日本語書き言葉均衡コーパス』形態論情報データベースの設計と実装 改訂版」
- 岡 照晃: 「言語研究のための電子化辞書」, コーパスと辞書, 講座 日本語コーパス 7, pp.1-28, 朝倉書店 (2019).
- 伝 康晴, 小木曽 智信, 小椋 秀樹, 山田 篤, 峯松 信明, 内元 清貴, 小磯 花絵: 「コーパス日本語学のための言語資源:形態素解析用電子化辞書の開発とその応用」, 日本語科学, Vol.22, pp. 101-123 (2007).
- 伝 康晴, 中村 純平, 小木曽 智信, 小椋秀樹: 「語種情報を用いた同表記異音語の解消」, 言語処理学会第14回年次大会, pp.69-72 (2008).
- Yasuharu Den, Junpei Nakamura, Toshinobu Ogiso, Hideki Ogura. A Proper Approach to Japanese Morphological Analysis: Dictionary, Model, and Evaluation, In Proceedings of the sixth international conference on Language Resources and Evaluation (LREC 2008), pp.1019-1024 (2008).
- 小木曽 智信, 小町 守, 松本 裕治: 「歴史的日本語資料を対象とした形態素解析」, 自然言語処理, Vol.20, No.5, pp.727-748 (2013).